原文链接 http://blog.piasy.com/2016/05/06/Perfect-Android-Model-Layer/
注:以下为加速网络访问所做的原文缓存,经过重新格式化,可能存在格式方面的问题,或偶有遗漏信息,请以原文为准。
前些日子在 Android Weekly{:target="blank"} 上看到了一篇介绍 SqlDelight 使用{:target="_blank"}的文章,虽然之前了解过 SqlDelight{:target="_blank"} 和 SqlBrite{:target="_blank"},但却一直没有尝试过。但这次我被文章中的例子惊艳到了,而且 SqlDelight 还能和 AutoValue{:target="_blank"} 兼容使用,进一步打消了我的顾虑,我就赶紧在 AndroidTDDBootStrap{:target="_blank"} 项目进行了尝试,并且甩掉了之前使用的 StorIO{:target="_blank"} 这个 ORM 库。迁移完毕之后我不得不惊叹,我 _遇见 了一套完美的安卓 model 层架构。本文所有的代码均来自我在 Github 上的 AndroidTDDBootStrap 项目{:target="_blank"}。
声明:本文已独家授权微信公众号Android程序员(AndroidTrending)在微信公众号平台原创首发。
整体架构
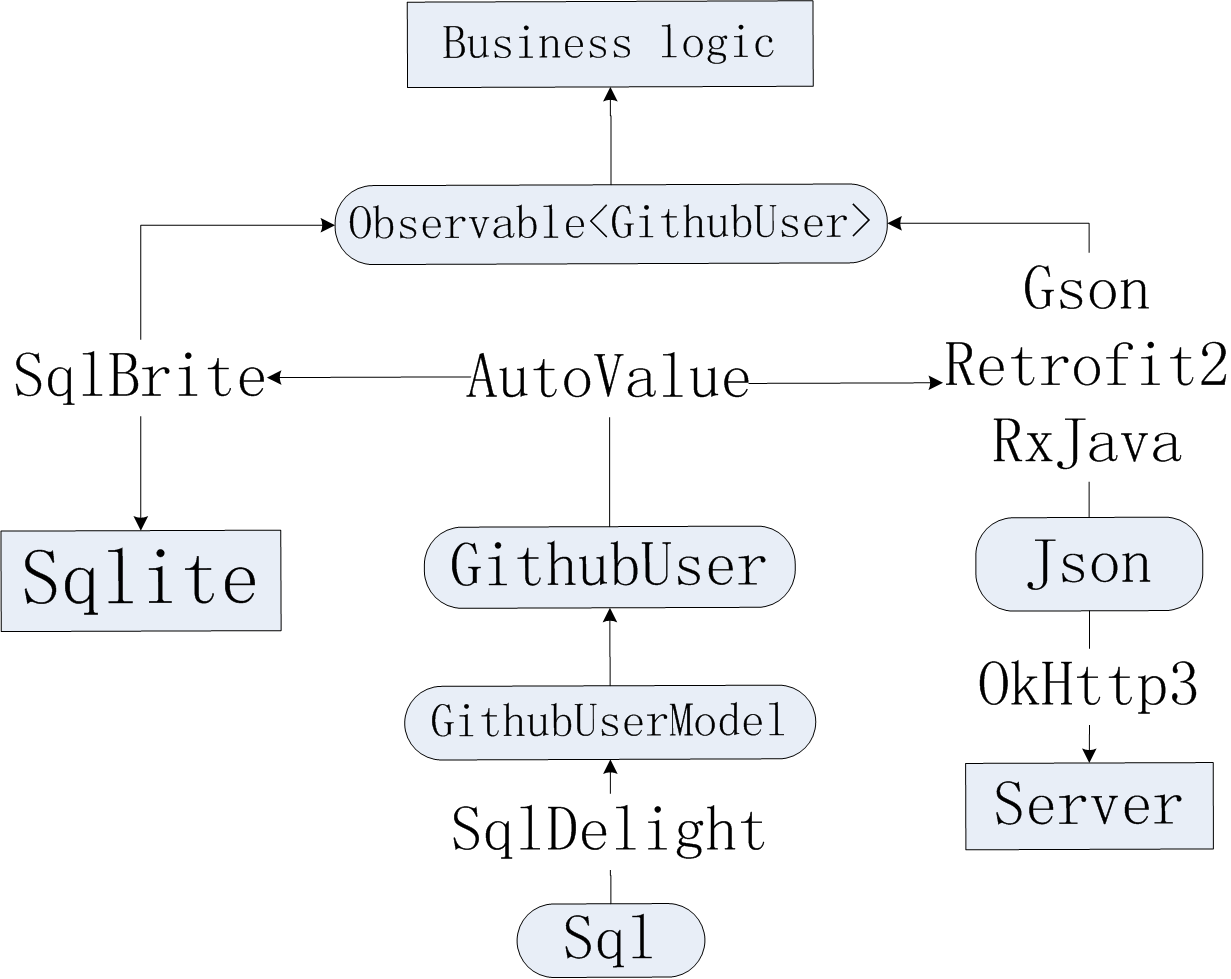
总的来说,就是:
- 利用 OkHttp 和 Retrofit 进行网络请求;
- 利用 SqlDelight、AutoValue 及其系列扩展生成我们的 model 类,大大减少我们需要编写的代码;
- 利用 Gson 进行 model 类的 Json 序列化和反序列化;
- 利用 SqlBrite 提供对数据库访问的 reactive API;
- 最后由于 Retrofit 和 SqlBrite 都提供了 reactive API,我们的业务逻辑代码就可以尽情享用响应式编程的强大了。
这里面可能有很多新鲜词汇,不要紧张,请接着往下看,下面将对每部分进行详细的展开。
网络请求
OkHttp{:target="_blank"} 和 Retrofit{:target="_blank"} 自是当仁不让了。这两尊大佛太有名了,我就不啰嗦了,一句话来说,OkHttp 是安卓6.0以后的官方 Http Client,而 Retrofit 则让我们只需要定义一个 Java interface 就可以发起 RESTful API 请求,它们都是 Square 公司的开源项目,这里我使用的分别是 Okhttp3 和 Retrofit2。
持久化
持久化模块当然就是这次新晋的主角 SqlDelight{:target="_blank"} 和 SqlBrite{:target="_blank"} 了。
SqlDelight 可以根据建表的 SQL 语句自动生成 Java model interface,interface 的每个方法就是这张表的每一列。例如这样:
CREATE TABLE GithubUsers (
id INTEGER PRIMARY KEY,
login TEXT NOT NULL,
avatar_url TEXT NOT NULL,
type TEXT NOT NULL,
created_at TEXT AS 'org.threeten.bp.ZonedDateTime' NULL
);
SqlDelight 的具体设置步骤可以参考其项目主页{:target="_blank"},SqlDelight 生成的 Java interface 如下(简洁起见,只保留了部分代码):
public interface GithubUserModel {
String TABLE_NAME = "GithubUsers";
...
String CREATE_TABLE = ""
+ "CREATE TABLE GithubUsers (\n"
+ " id INTEGER PRIMARY KEY,\n"
+ " login TEXT NOT NULL,\n"
+ " avatar_url TEXT NOT NULL,\n"
+ " type TEXT NOT NULL,\n"
+ " created_at TEXT NULL\n"
+ ")";
@Nullable
Long id();
@NonNull
String login();
@NonNull
String avatar_url();
@NonNull
String type();
@Nullable
ZonedDateTime created_at();
final class Mapper<T extends GithubUserModel> implements RowMapper<T> {
...
}
class GithubUserMarshal<T extends GithubUserMarshal<T>> {
...
}
}
怎么样,是不是省了一大段代码?
上面 SQL 语句中的 AS 语句是用来告知 SqlDelight,created_at 这一列是自定义类型,在数据库中以 TEXT 存储,但接口的类型是 ZonedDateTime。为此我们需要实现一个 ColumnAdapter 子类,用于 String 和 ZonedDateTime 的互相转换。adapter 代码很简单:
public class ZonedDateTimeDelightAdapter implements ColumnAdapter<ZonedDateTime> {
private final DateTimeFormatter mDateTimeFormatter;
public ZonedDateTimeDelightAdapter(final DateTimeFormatter dateTimeFormatter) {
mDateTimeFormatter = dateTimeFormatter;
}
@NonNull
@Override
public ZonedDateTime map(final Cursor cursor, final int columnIndex) {
return mDateTimeFormatter.parse(cursor.getString(columnIndex), ZonedDateTime.FROM);
}
@Override
public void marshal(final ContentValues values, final String key,
@NonNull final ZonedDateTime value) {
values.put(key, mDateTimeFormatter.format(value));
}
}
SqlDelight 生成的代码中,Mapper 用来把数据库 Cursor 对象转化为我们定义的 Java 类型,GithubUserMarshal 则用于把 Java 类型的对象转化为 ContentValues 对象,用于存储到数据库中。
Immutable/Value types
Immutable/Value types 这个概念对有些朋友来说可能还比较陌生,简单来说就是一个数据对象一旦构造完成,就再也无法修改了。这样有什么好处呢?最大的好处就是多线程访问可以省去很多同步控制,因为它们是不可变的,一旦构造完成,就不会存在多线程竞争访问问题了。更多关于 immutable 的介绍,可以参阅 wikipedia{:target="_blank"}。
为了让我们的对象具有 immutable 的特性,我使用了 Google 的 AutoValue{:target="_blank"} 库,AutoValue 可以根据我们定义的 abstract 类自动生成具有 immutable 特性的实现类,还能替我们处理好 equals,null 安全性,以及实现 builder 模式。为此我们需要创建一个 abstract 类来实现 SqlDelight 生成的接口:
@AutoValue
public abstract class GithubUser implements GithubUserModel {
public static final Mapper<GithubUser> MAPPER = new Mapper<>
(AutoValue_GithubUser::new, new ZonedDateTimeDelightAdapter());
@NonNull
public static Builder builder() {
return new AutoValue_GithubUser.Builder();
}
@AutoValue.Builder
public abstract static class Builder {
public abstract Builder id(@Nullable Long id);
public abstract Builder login(String login);
public abstract Builder avatar_url(String avatarUrl);
public abstract Builder type(String type);
public abstract Builder created_at(@Nullable ZonedDateTime createdAt);
public abstract GithubUser build();
}
public static class Marshal extends GithubUserMarshal<Marshal> {
...
}
}
只需要给我们的类加上 @AutoValue 注解, 注解处理器就会为我们生成 abstract 类的实现类 AutoValue_GithubUser,至此就完成了和 AutoValue 的集成了。
一开始我注意到,代码里面还是有一点 boilerplate 的,我们需要在 GithubUser 里面加一个 MAPPER 成员,还需要一个 GithubUserMarshal 的子类。但仔细一想,就明白了它们其实是必须的,而且是能够减少我们的 boilerplate 的。
前面提到,mapper 是用来把数据库的 Query 对象 map 为数据对象的,为了省去我们每次进行这样的 map 操作时 new 一个 mapper,我们只需要在此处 new 一次即可。而 marshal 类则可以封装我们把数据对象 map 为 ContentValues 时的公用逻辑,也是非常有用的。marshal 的作用类似于 builder,但它的最终结果是 ContentValues 对象,用于保存到数据库,并不是 GithubUser 对象,所以我们仍需一个 builder。因为我们的数据类不仅仅用于反序列化 API 返回的数据以及从 DB 中读取数据,构造对象的需求是真实存在且必要的。
这部分最后值得一提的就是 RetroLambda 了,使用了 method reference 之后,我们创建 MAPPER 对象的代码也变得简洁了不少。之前由于 BUCK 构建系统和 RetroLambda 不能一起工作,所以将近一年没有体验过 lambda 的简洁之美了,几天前终于解决了这个问题{:target="_blank"},现在又能同时享受 BUCK 的飞速构建和 lambda 的极致简洁了!
数据库访问
数据库访问使用的就是上文提到的 SqlBrite{:target="_blank"} 了。SqlBrite 对 SQLiteOpenHelper 和 ContentResolver 进行了轻量的封装,同时为查询操作提供 Reactive API(响应式编程),后续对数据表的操作,都会触发 Observable 的更新,让我们各个界面的数据同步问题得以优雅的解决。
响应式编程已经被提出来很久了,RxJava 这个 Java 语言的响应式编程库也发布两年了,它和我们熟知的 观察者模式 有一定相似之处,订阅者可以订阅数据源,除了观察者模式,RxJava 还具备对事件流的强大处理能力,更多关于 RxJava 的内容,建议阅读这篇给 Android 开发者的 RxJava 详解{:target="_blank"}。
设想这样的场景,我们有一个好友列表界面,展示每个好友的信息,其中一项就是备注名称,点击某个好友的那一列,我们就进入到一个好友的 profile 界面,展示好友完整的个人信息,再点击这个界面的编辑按钮,进入到一个编辑备注名称的界面。在最后的编辑界面编辑完成之后,我们怎么保证前面的两个界面上展示的数据都能够同步更新?
实现方法有很多,但我觉得下面的这种方式几乎是最优的:所有界面展示的数据都是直接从数据源(DB)获取的,数据源一旦更新,就通知所有的界面更新数据,这样所有的界面显示的数据都是不需要维护的,这和 React 的 props 思想类似,我们不是通过修改(维护)界面持有的数据来更新界面,而是每次都给界面一个完整的最新的数据,这样能很大程度上简化界面的代码。实际上数据本来就只有一份(数据源那里),这样做既省去了我们进行数据一致性维护的复杂逻辑,也是非常直观的。
SqlBrite 提供的 Reactive API 很好地符合这一特性,而 Rx 提供的强大的事件流处理机制,也让我们后续的有些逻辑实现起来非常简洁。此前我一直使用 StorIO{:target="_blank"} 来提供 Rx API,除了 Rx API,StorIO 还对数据库访问进行了高度封装,我们访问数据库只需要进行三种操作:get,put,delete。但它的封装程度过高,导致我们很难定制一些特定的需求。
例如全量更新一张数据表,StorIO 只能先执行一次 delete all,在执行一次 put all,而它们又是无法在同一个 transaction 中进行的,实际上 StorIO 并没有暴露出 transaction 接口,它只是保证 put 一个 list 时会使用 transaction。这样一次全量更新会触发 subscriber 的两次更新,会让我们的界面在强制刷新时经历一个 有 -> 无 -> 有 的变化,比较影响用户体验。
SqlBrite 则和 StorIO 完全相反,几乎没有进行封装,我们使用的都是 DB 的 API,API 的封装程度越低,我们所获得的能力就越强大,当然我们需要为此付出相应的代价。使用 SqlBrite 进行 DB 访问时,我们还需要和 Cursor 打交道,不过这当然难不倒我们这群聪明的程序员,所以我才果断放弃了 StorIO。我们完全可以自己在 SqlBrite 的基础上进行一些封装,简化使用方的代码,同时我们又具备了更高的可定制能力。
Json 序列化与反序列化
经过上面的步骤,我们已经可以完美的实现数据的本地存储了,但是我们还得和服务器交互呢,上面的流程中,Json 如何集成呢?这里我们使用 Google 的 Gson{:target="_blank"} 进行 Json 的序列化与反序列化。
使用了 AutoValue 之后,我们的代码中引用的都是 GithubUser 这样的抽象类,而不是 AutoValue_GithubUser 这样的实现类,这当然是更好的,更 SOLID。但是 Gson 如何知道一段 Json 字符串应该反序列化为 AutoValue_GithubUser 这样的实现类呢?
在这里我引入了 auto-value-gson{:target="_blank"} 来解决这个问题,它是一个 AutoValue 的扩展,可以自动生成 gson adapter 代码。关于 AutoValue 的扩展,感兴趣的朋友可以阅读 auto-value-gson 作者的这篇文章{:target="_blank"}。AutoValue 及其系列扩展可以大大减少我们要编写的代码,而且生成的代码正确性和效率都经过了广泛的测试,值得信赖,非常建议大家了解和使用。
auto-value-gson 需要我们为 GithubUser 类加入一个静态方法:
@AutoValue
public abstract class GithubUser implements GithubUserModel {
...
public static TypeAdapter<GithubUser> typeAdapter(Gson gson) {
return new AutoValue_GithubUser.GsonTypeAdapter(gson);
}
...
}
auto-value-gson 会为我们生成一个 GsonTypeAdapter 类,用于进行 GithubUser 类的序列化反序列化。生成的代码是这样的:
public static final class GsonTypeAdapter extends TypeAdapter<GithubUser> {
private final TypeAdapter<Long> idAdapter;
private final TypeAdapter<String> loginAdapter;
private final TypeAdapter<String> avatar_urlAdapter;
private final TypeAdapter<String> typeAdapter;
private final TypeAdapter<ZonedDateTime> created_atAdapter;
public GsonTypeAdapter(Gson gson) {
this.idAdapter = gson.getAdapter(Long.class);
this.loginAdapter = gson.getAdapter(String.class);
this.avatar_urlAdapter = gson.getAdapter(String.class);
this.typeAdapter = gson.getAdapter(String.class);
this.created_atAdapter = gson.getAdapter(ZonedDateTime.class);
}
@Override
public void write(JsonWriter jsonWriter, GithubUser object) throws IOException {
jsonWriter.beginObject();
if (object.id() != null) {
jsonWriter.name("id");
idAdapter.write(jsonWriter, object.id());
}
jsonWriter.name("login");
loginAdapter.write(jsonWriter, object.login());
jsonWriter.name("avatar_url");
avatar_urlAdapter.write(jsonWriter, object.avatar_url());
jsonWriter.name("type");
typeAdapter.write(jsonWriter, object.type());
if (object.created_at() != null) {
jsonWriter.name("created_at");
created_atAdapter.write(jsonWriter, object.created_at());
}
jsonWriter.endObject();
}
@Override
public GithubUser read(JsonReader jsonReader) throws IOException {
...
}
}
简洁起见,我省略了 read 方法的代码。这里我们可以看到,adapter 的实现完全避免了反射的使用,这一点对性能也将会有提升(具体有多大的提升,~~我打算做个测试~~ 可以参考文末的测试结果),关于反射的性能问题,感兴趣的朋友可以阅读我翻译的 NimbleDroid 团队的这篇文章{:target="_blank"}。
16.5.17 更新:之前由于 auto-value-gson 不能自动生成 adapter factory,所以我引入了自己的一个 fork,但其中使用了反射,会造成严重的性能问题,具体可以查看文末的附录。而新版本 auto-value-gson 支持自动生成 adapter factory,所以这部分就切换回了原版。
除了 adapter 之外,auto-value-gson 还为我们生成了 adapter factory,让我们仅需一行代码就能完成注册。
生成的 adapter factory 代码如下:
public final class AutoValueGsonTypeAdapterFactory implements TypeAdapterFactory {
@Override
public <T> TypeAdapter<T> create(Gson gson, TypeToken<T> type) {
Class<T> rawType = (Class<T>) type.getRawType();
if (rawType.equals(GithubUser.class)) {
return (TypeAdapter<T>) GithubUser.typeAdapter(gson);
} else {
return null;
}
}
}
Gson 的构造过程中我们只需要注册一个 adapter factory 即可:
new GsonBuilder()
.registerTypeAdapterFactory(new AutoValueGsonTypeAdapterFactory())
.create();
完成!是不是很简洁!
小结
好了,至此和服务器 API 交互、数据库存储、序列化反序列化一整套流程都已经通了,是不是很优雅 :)
到这里内容已经有点多了,不能更长了。还剩下一些 parcelable,ZonedDateTime,null safety,rx error handling,config injection以及测试相关的内容,我打算放到下篇中。敬请期待!
致谢
非常感谢 安卓程序员 公众号的运营者 汤涛 大哥对本文提出的宝贵建议。
附:AutoGson 反射性能测试
为了测量 type adapter factory 是否使用反射、序列化时是否使用反射的性能区别,我做了几组简单地实验:
- 在 hello world 工程{:target="_blank"}中
- 创建 adapter 时使用反射,序列化时不使用反射(
toJson函数指定类型),记为 create; - 创建 adapter 时不使用反射,序列化时使用反射(
toJson函数不指定类型),记为 toJson; - 创建 adapter 时使用反射,序列化时使用反射,记为 create & toJson;
- 创建 adapter 时不使用反射,序列化时不使用反射,记为 reflectless;
- 创建 adapter 时使用反射,序列化时不使用反射(
- 在 AndroidTDDBootStrap 工程中进行同样的测试
实验都是新创建 Gson 对象,并创建新对象,调用 toJson 10000 次。实验在两台手机上进行:
- 三星 A7,安卓 4.4.4,8 核 CPU,2 GB RAM
- 华为 3C,安卓 4.4.2,4 核 CPU,2 GB RAM
测试结果如下,单位纳秒:
- | reflectless | create | toJson | create & toJson A7, hello world | 1,830,788,333 | 3,076,125,832 | 5,044,041,092 | 5,594,355,988 A7, AndroidTDDBootStrap | 1,872,459,687 | 3,180,990,155 | 5,207,894,529 | 6,128,111,873 3C, hello world | 5,927,091,874 | 8,829,257,395 | 16,688,314,635 | 17,324,313,488 3C, AndroidTDDBootStrap | 4,886,309,062 | 9,427,969,531 | 18,550,120,207 | 19,450,675,780
首先我们看看只利用反射创建 adapter 的开销:在 A7 上,hello world 工程中耗时增加 68%,AndroidTDDBootStrap 工程中耗时增加 69.8%;在 3C 上,hello world 工程中耗时增加 48.9%,AndroidTDDBootStrap 工程中耗时增加 92.9%。我们可以看到,每次创建 adapter 都使用反射,耗时增加了 48.9% ~ 92.9%。
这里需要注意,为了让运行结果可测量,我反复创建了新的 Gson 对象 10000 次,实际使用中,我们通常会使用一个全局单例的 Gson 对象,而 Gson 对 adapter 进行了缓存处理,所以一个 adapter 只会利用反射创建一次。
再来看看只利用反射进行序列化的开销:在 A7 上,hello world 工程中耗时增加 175.5%,AndroidTDDBootStrap 工程中耗时增加 178.1%;在 3C 上,hello world 工程中耗时增加 181.5%,AndroidTDDBootStrap 工程中耗时增加 279.6%。我们可以看到,每次执行 toJson 都使用反射,耗时增加了 175.5% ~ 279.6%。
最后我们看看利用反射创建 adapter 和进行序列化的开销:在 A7 上,hello world 工程中耗时增加 205.5%,AndroidTDDBootStrap 工程中耗时增加 227.2%;在 3C 上,hello world 工程中耗时增加 192.2%,AndroidTDDBootStrap 工程中耗时增加 298%。我们可以看到,每次执行 toJson 都使用反射,耗时增加了 192.2% ~ 298%。
所以,Json 序列化和反序列化时,对反射的使用还是非常影响性能的,而利用 auto-value-gson,我们可以轻易地避免这块额外的性能开销,唯一需要注意的是,调用 toJson 时,务必带上第二个参数。