原文链接 http://www.lelovepan.cn/2015/11/25/%E5%8F%B0%E5%A4%A7%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%9F%B3%E7%AC%94%E8%AE%B04-3.html
注:以下为加速网络访问所做的原文缓存,经过重新格式化,可能存在格式方面的问题,或偶有遗漏信息,请以原文为准。
将概率统计联系到机器学习上
表4-1 机器学习与统计中的对比 罐子小球 机器学习 未知的橙色小球比例 某一确定的假设在整个X输入空间中,输入向量x满足条件 的占整个输入空间的比例 抽取的小球∈整个罐子中的小球 训练输入样本集 整个数据集X 橙色小球 假设h作用于此输入向量x与给定的输出不相等 绿色小球 假设h作用于此输入向量x与给定的输出相等 小球样本是从罐子中独立随机抽取的 输入样本x是从整个数据集D中独立随机选择的 该表来自博客园.杜少
我们将上一节的罐子抽样问题类比到机器学习:我们要求target function f。如果我们求出的h(x)=f(x),那么就是说h(x)是对的,否则h(x)是错的。我们手上有training examples,D:(x1,y1),....,(xN,yN)。所以可以求出在training examples上h(x)的错误率,但是还是不知道在整个样本上的错误率。
现在,我们联系上一节的Hoeffering不等式。假定一个确定的h,我们能够知道:
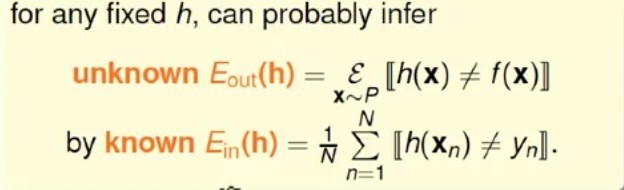
E(in)代表给出来的,在我们手上的样本的错误率。E(out)代表在所有样本上的错误率。

如果training examples够大(抽样样本很大),那么‘Ein(h)=Eout(h)’ 很大可能是相似的(is probably approximately correct...PAC)。
然而,不知道你有没有糊涂!我们这里一直是给定一个h(假设函数),然后如果它的预测错误率E(error)很小,那么它估计在整体上的预测错误率很小,这仅仅可以成为一种验证方法。但是如果Hyposis set 本身就很大呢?我们可能很难选出一种h,来保证E(error)很小(无论在训练数据集还是整体上)。