原文链接 http://www.lelovepan.cn/2018/11/07/NMT-tutorial.html
注:以下为加速网络访问所做的原文缓存,经过重新格式化,可能存在格式方面的问题,或偶有遗漏信息,请以原文为准。
这里是示例的Jupyter Notebook。
最近详细研究了研究TensorFlow的seq2seq库。为了能实现一个神经语言翻译模型,我希望能尽快了解一个大概。这里我就仅仅想知道“我需要清除知道关于这个库的哪些细节”,而不是一个“8层双向基于注意力机制使用集束搜索…的网络”吧啦吧啦有惊人的效果。我这里就像怎么来实现最基本的NMT模型。翻了好多材料来寻找一份“简单”的参考代码时,我一点也不惊讶。
入门教程需要定睛在基本概念上
别误解,Tensorflow 官方教程的确很棒,并且提供了完善的概念基础。但是剩下90%的代码非常的复杂,主要用在提高性能而导致修饰过多,没有怎么考虑基础概念。这对于很多初学者相当的不友好—在初学者和超级复杂的代码结构前有很大的鸿沟。我这里就是要充当这个沟通初学者和NMT模型的桥梁,让NMT模型容易掌握。撸起袖子就是干!
什么是神经语言翻译机器
NMT是最新的一种机器翻译模型(也就是将一个句子/短语从源语言翻译成目标语言)。NMT目前保持着state-of-the-art 性能,并且一点点在接近人类。NMT到底长啥样呢?它有一下三个最重要的组成构件:
- 嵌入(Embedding)层(源语言与目标语言词汇都有): 将词转换为词向量。
- 编码器:LSTM单元(可以多层)编码源语言句子。
- 解码器:LSTM单元(可以多层)解码 编码后的源语言句子。
他们按照如下方式来组装的:
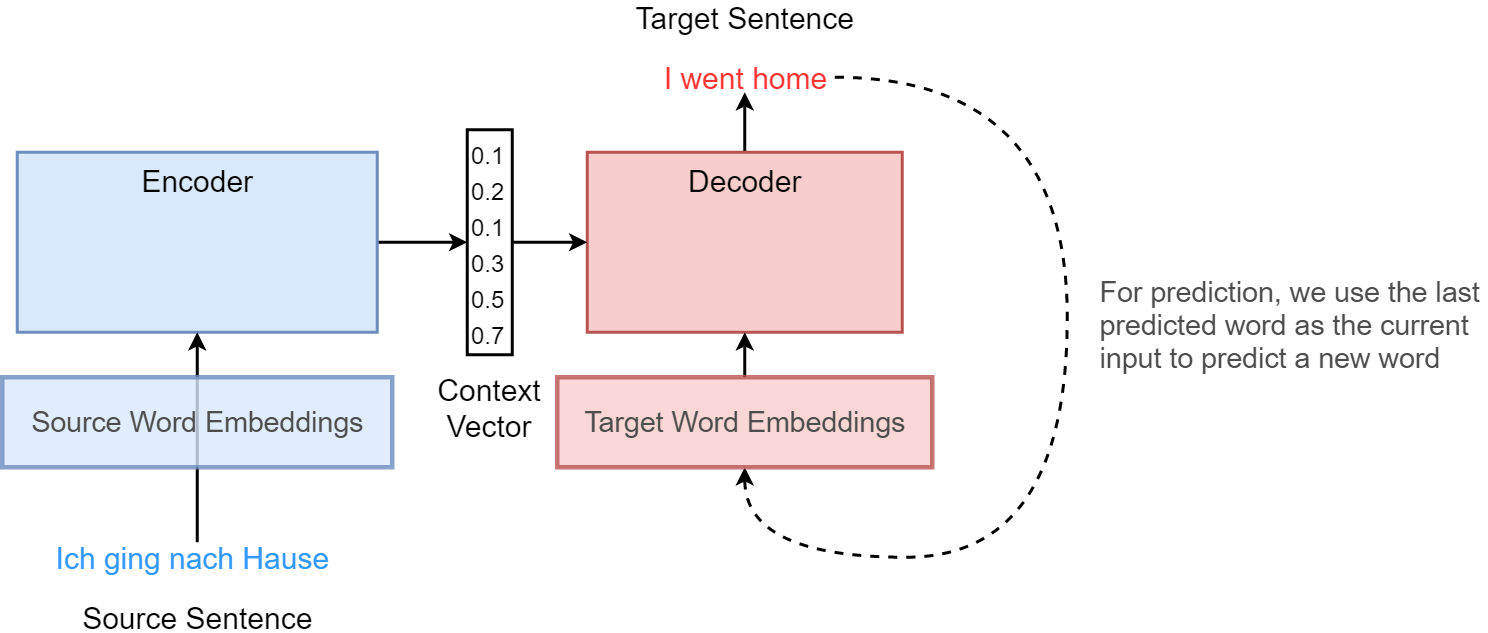
这描述了一个“已训练完成”的NMT模型接口。编码器和解码器都是基本LSTM单元。这里可以使用更深的LSTM层或者双向深度LSTM来得到更好的性能。一旦你掌握了整个基础,这些细节很容易完成。这里我们关注基础部分。注意本不打算介绍NMT背后的理论,而是如何实现NMT。如果你对理论还不是很熟悉,我建议你先读一些相关文献然后再来看本文。
这些模型也被广泛称为序列到序列(Seq2Seq)模型,因为我们是将一个词语序列放入,然后得到任意长度的翻译后的词语序列。文章Sequence to Sequence 是第一个提出这种结构的。许多有趣的现实问题例如机器翻译,对话机器人,文本摘要之类都使用这种结构。
tensorflow.seq2seq是什么?
seq2seq基本上就是tensorflow对我们实现seq2seq模型时所进行的复杂工作的包装。如果你要实现上图中的这种工作流程结构,那真是相当的麻烦。举例来说你需要处理以下这些事情:
- 不是所有句子都有同样的长度,所以在批量化处理句子时相当的有技巧性。
- 必须保证解码器总是使用最新的编码器状态来初始化。 相信我。随着你越来越想让你的模型更好,更多的升级会让工作越来越困难。Seq2seq库让开发显得非常的方便。 ## 直接干吧(先别管性能问题) 上面对NMT有个大致概览。下面直接来实现一个,不到大约50行代码就可以。 ### 定义输入,输出和掩码(masks) 我们首先定义用于接受源语言句子单词(enc_train_inputs )和目标语言句子单词(dec_train_inputs)的placeholders。然后再为解码器定义掩码(dec_label_masks)在训练期间来屏蔽(mask out)真正的目标语句长度外的元素。这一步很重要,因为在处理一批数据的时候,需要填充(padding)一些特殊符号(比如)来缩短句子,使一批数据内的所有句子有同样的长度(同样包括截断很长的句子)。
enc_train_inputs, dec_train_inputs = [],[]
"""Defining unrolled training inputs for encoder"""
for ui in range(source_sequence_length):
enc_train_inputs.append(tf.placeholder(tf.int32, shape=[batch_size], name='enc_train_inputs_%d'%ui) )
dec_train_labels, dec_label_masks = [], []
""" Defining unrolled training inputs for decoder"""
for ui in range(target_sequence_length):
dec_train_inputs.append(tf.placeholder(tf.int32, shape=[batch_size], name='dec_train_inputs_%d'%ui))
dec_train_labels.append(tf.placeholder(tf.int32, shape=[batch_size], name='dec_train_outputs_%d'%ui))
dec_label_masks.append(tf.placeholder(tf.float32, shape=[batch_size], name='dec_label_masks_%d'%ui))
定义词嵌入相关操作
现在定义词嵌入相关的操作。词嵌入操作是为了从enc_train_inputs和dec_train_inputs中获取对应的词向量。这里我已经提前做好了两种语言的词嵌入,这里用numpy矩阵来存储(de-embeddings.npy和en-embeddings.npy)。使用tf.convert_to_tensor操作便可以将数据以tensor的方式加载进入tensorflow。当然你也可以将encoder_emb_layer和decoder_emb_layer作为变量来初始化并结合起来训练。这也就是把tf.convert_to_tensor转为tf.Variable(...)。
接下来我们查找(lookup)一批数据训练时用到的源语言词汇(encoder_emb_inp)和目标语言词汇(decoder_emb_inp)对应的词嵌入。encoder_emb_inp是元素为 tensor的 source_sequence_length的列表,tensor形状为[batch_size, embedding_size]。我们同样定义了名为 enc_train_inp_lengths的placeholder,其中包含了一批数据中每个句子的长度。稍后便会用到。最后tf.stack操作会堆叠(stack)所有列表中的元素并产生一个大小为[source_sequence_length, batch_size, embedding_size]的tensor。这是一个时间为主序列(time_major)的tensor。同样来定义decoder_emb_inp。
"""Need to use pre-trained word embeddings"""
encoder_emb_layer = tf.convert_to_tensor(np.load('de-embeddings.npy'))
decoder_emb_layer = tf.convert_to_tensor(np.load('en-embeddings.npy'))
"""looking up embeddings for encoder inputs"""
encoder_emb_inp = [tf.nn.embedding_lookup(encoder_emb_layer, src) for src in enc_train_inputs]
encoder_emb_inp = tf.stack(encoder_emb_inp)
"""looking up embeddings for decoder inputs"""
decoder_emb_inp = [tf.nn.embedding_lookup(decoder_emb_layer, src) for src in dec_train_inputs]
decoder_emb_inp = tf.stack(decoder_emb_inp)
""" to contain the sentence length for each sentence in the batch"""
enc_train_inp_lengths = tf.placeholder(tf.int32, shape=[batch_size], name='train_input_lengths')
定义编码器
三行代码定义编码器!
encoder_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units)
initial_state = encoder_cell.zero_state(batch_size, dtype=tf.float32)
encoder_outputs, encoder_state = tf.nn.dynamic_rnn(encoder_cell, encoder_emb_inp, initial_state=initial_state, sequence_length=enc_train_inp_lengths, time_major=True, swap_memory=True)
可见,定义解码器非常简单(除非你偏执地要进行性能优化而专注于具体实现细节)。我们首先定义encoder_cell,这里是使用"num_units个LSTM单元"作为编码器结构。如果想让LSTM网络更深一些的话,可以定义一个LSTM单元数组(an array of such cells)。之后初始化编码器状态为0。在第三行中的dynamic_rnn函数可以处理不定长结构的序列(完美契合我们的任务)。该函数使用 encoder_cell结构,使用 enc_emb_inp 作为结构的输入,每个序列的长度定义在enc_train_inp_lengths中。最后再说输入序列中的time_major和swap_memory问题(性能优化)。
定义解码器
decoder_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units)
projection_layer = Dense(units=vocab_size, use_bias=True)
""" Helper"""
helper = tf.contrib.seq2seq.TrainingHelper(
decoder_emb_inp, [tgt_max_sent_length-1 for _ in range(batch_size)], time_major=True)
""" Decoder"""
if decoder_type == 'basic':
decoder = tf.contrib.seq2seq.BasicDecoder(
decoder_cell, helper, encoder_state, output_layer=projection_layer)
elif decoder_type == 'attention':
decoder = tf.contrib.seq2seq.BahdanauAttention(
decoder_cell, helper, encoder_state, output_layer=projection_layer)
""" Dynamic decoding"""
outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(
decoder, output_time_major=True, swap_memory=True)
解码器需要的工作稍微有点多,但也不超过10行。首先定义decoder_cell,然后是projection_layer,这就是softmax层,负责输出翻译后的one-hot-encoded词。定义的helper通过序列中的输入来迭代的产生输出(And we define a helper that iteratively produces in the inputs in the sequence)。之后定义最重要的部分—解码器。目前有很多种不同的解码结构供选择,参考这里。示例中提供了两种不同的解码器。解码器部分的意思:
“BahdanauAttention类型的解码器使用decoder_cell结构,helper用来从输入获取数据送入解码器中,使用编码器最后一步的状态来作为解码器的初始状态,使用projection_layer(也就是softmax层)来预测”
先别管上面的东西了,以后再说。
为什么我们需要最后一步编码器的状态来作为第一步解码器的状态?
这是编码器与解码器唯一相连的部分了(上图中解码器与编码器相连的箭头)。换句话说,编码器最后一步的状态提供了解码器预测翻译所需的上下文。编码器最后一步的状态可以理解为与语言无关的思想向量(The last state of the encoder can be interpreted as a "language-neutral" thought vector)。
什么是BahdanauAttention?
我们在BasicDecoder部分定义了两种解码器其中一种基本上就是一个标准LSTM和BahdanauAttention组成,BahdanauAttention比标准解码器更加复杂,但是性能更好。相对于标准解码器,编码器被迫精简句子中所有信息(主语,宾语,依存关系,语法…)到一个固定长度的向量,这是标准解码器唯一能够访问到的部分。从编码器获取更多的信息不就行了吗?BahdanauAttention让解码器可以在解码时访问完整的编码器历史状态,而不是仅仅依靠最后一个状态向量。tensorflow的seq2seq库提供了内置的功能机制,所以你无需担心底层机制。
新引入的projection层是个啥?
实际上即便没有这个层,我们依然可以从解码器访问到数据———肯定有办法在每一步解码时将解码器状态映射为某种字典预测(some vocabulary prediction)。实际上这就是projection_layer做的。 最后,我们使用dynamic_decode来从projection_layer中解码翻译并得到输出。output_time_major选项说明输出是以时间为主轴。
定义Loss
既然已经知道了输入,真实标签,预测标签,那么便可定义loss了。
logits = outputs.rnn_output
crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=dec_train_labels, logits=logits)
loss = (tf.reduce_sum(
crossent*tf.stack(dec_label_masks)) / (batch_size*target_sequence_length ) )
注意我们如何使用dec_label_masks来遮掩(mask out)loss中不想要的标签。这是非必须的。
得到预测
train_prediction = outputs.sample_id
这行很简单。
优化器
with tf.variable_scope('Adam'):
adam_optimizer = tf.train.AdamOptimizer(learning_rate)
adam_gradients, v = zip(*adam_optimizer.compute_gradients(loss))
adam_gradients, _ = tf.clip_by_global_norm(adam_gradients, 25.0)
adam_optimize = adam_optimizer.apply_gradients(zip(adam_gradients, v))
with tf.variable_scope('SGD'):
sgd_optimizer = tf.train.GradientDescentOptimizer(learning_rate)
sgd_gradients, v = zip(*sgd_optimer.compute_gradients(loss) )
sgd_gradients, _ = tf.clip_by_global_norm(sgd_gradients, 25.0)
sgd_optimize = sgd_optimizer.apply_gradients(zip(sgd_gradients, v))
起始阶段使用Adam优化器(比如,前10000次使用Adam),之后转为SGD。之所以这么做是因为如果一直使用Adam优化器的话会出现奇怪的结果。梯度裁剪可以避免出现梯度爆炸。
真正的翻译任务:德语到英语
所有训练工作做完了,剩下的就是在真正的翻译任务中使用了。这里我们使用 WMT’14 English-German data 。这里我做了一份数据集使用指南,所以你只需要下载就可以了。 Jupyter Notebook: 这里。 以下是需要下载的数据集列表。
- train.en(大)
- train.de(大)
- vocab.50k.en
- vocab.50k.de
- en-embeddings.npy
- de-embeddings.npy 两份语料的词嵌入(每份大约25Mb)已经做好,可以使用jupyter notebook直接使用。 ### 结果 展示一些这个翻译器的成果。Actual是真实输入编码器的德语翻译成的英语句子。predicted是解码器预测的结果。在这里,我们使用特殊字符**代替在词汇表中未找到的单词。 500步后... > Actual: To find the nearest car park to an apartment , have a look at this map link . > Predicted: The the the hotel of the , the the the , 2500步后... > Actual: Public parking is possible on site and costs EUR 20 per day . > Predicted: If parking is possible at site ( costs EUR 6 per day . ## 如何提高NMT性能 我们这里的目标是理解NMT基本的一些概念。但是不能止于这里。人生总得有点追求啊,所以还得想想怎么提高性能。这里我提供几点如何提高NMT性能的思路:
- 增加更多的层来辅助系统捕获更多语言方面的细节。
- 使用双向LSTM。双向LSTM可以从两个方向来读取文本,这让他更厉害。
- 使用注意力机制。注意力机制可以使解码器能够访问编码器完整的历史状态。
- 使用混合(hybrid)NMT:混合NMT可以使用不同的方式来处理生僻词,而不是直接替换它们。 当然方法远不止上面这几种,希望本文对你理解NMT有所帮助。