原文链接 http://www.lelovepan.cn/2019/01/08/%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E5%85%A5%E9%97%A8.html
注:以下为加速网络访问所做的原文缓存,经过重新格式化,可能存在格式方面的问题,或偶有遗漏信息,请以原文为准。
这篇文章是将会是知识图谱系列的第一篇,也算是学习中的一些笔迹吧,希望能够讲清楚一些基本概念。
前世今生
早在12年Google就提出了知识图谱的概念(Knowledge Graph)。实际上知识图谱技术由来已久,只是不停地换名字:专家系统,与以往,链接数据….我们在各个搜索引擎中也看到了相关的应用:
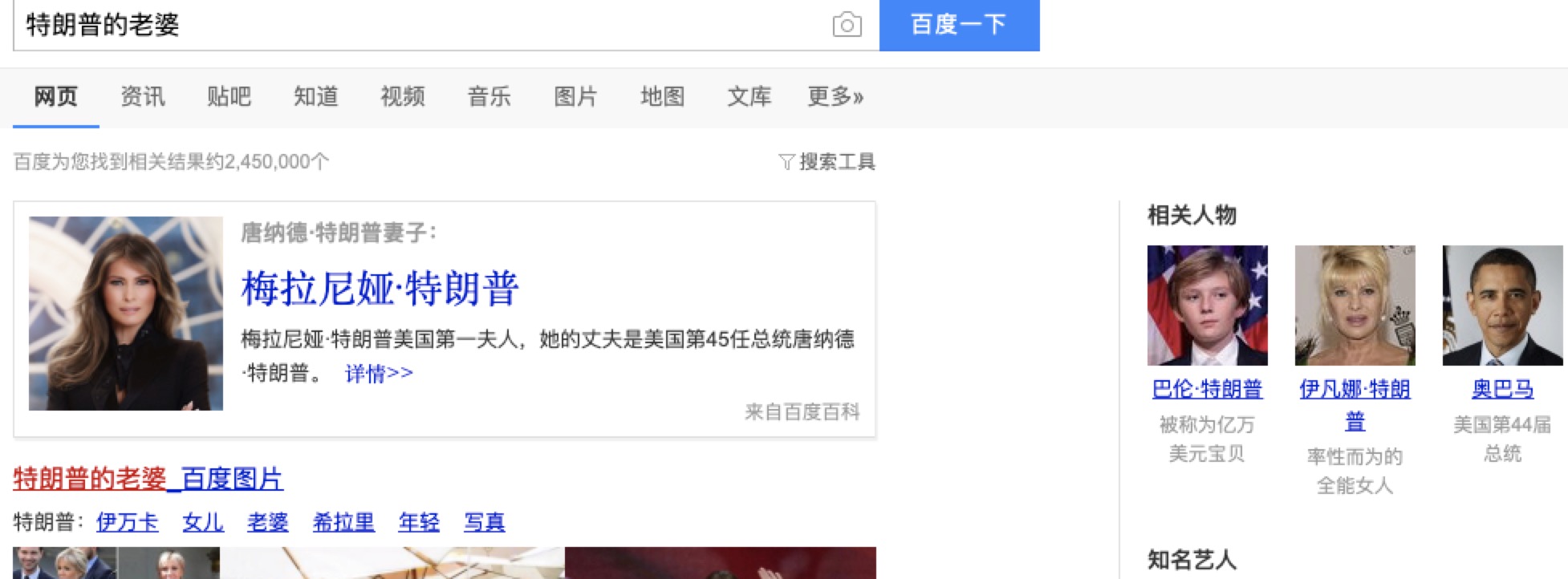
不同于以前基于文本的搜索方式,知识图谱不是简单的进行文本匹配,而是理解文本背后的语义信息,然后返回相关的结构化的信息。
知识图谱目前没有一个标准化的定义,借用“Exploiting Linked Data and Knowledge Graphs in Large Organisations”中的定义:
A knowledge graph consists of a set of interconnected typed entities and their attributes.
也就是一些相互连接的实体和他们的属性所构成的图,也就是一条条知识。每条知识表示为一个SPO三元组(Subject-Predicate-Object)。

RDF
常用RDF(Resource Description Framework)来表示这种三元关系。RDF中有International Resource Identifiers(IRIs), blank nodes和literals。IRI可以看做是URL或URI的泛化与推广,定义了唯一的实体与资源。 literal为字面量,比如特朗普原名为 Donald John Trump。blank node可以理解为没有IRI和literal的资源。 将罗纳尔多这个实体表示出来:

RDF扩展:RDFS/OWL
RDF这么抽象的描述语言,表达能力还是有限,无法区分类与对象,无法定义描述关系。比如在上面罗纳尔多的途中,如果想定义罗纳尔多是人,里约热内卢是地方,人与地方的关系,人的属性等,RDF就无能为力了。这时候我们就需要RDFS和OWL这两种模式语言/本体语言(schema/ontology language)了。
RDFS定义了一些基础词汇:
1. rdf:class 定义类
2. rdfs:domain 表示属性属于哪个类别
3. rdfs:range 描述该属性的取值类型
4. rdfs:subClassOf 描述该类的父类。比如运动员类是人的子类。
5. rdfs:subProperty. 用于描述该属性的父属性。
用图来描述这个数据层与模式层:

RDFS的扩展OWL
OWL额外又提供了两个功能:快速灵活的数据建模能力与高效的自动推理。 描述属性特征的词汇:
1. owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义“位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。
2. owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义“认识”是具有对称性的属性,若A认识B,那么B肯定认识A。
3. owl:FunctionalProperty. 表示该属性取值的唯一性。 例如,我们定义“母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。
4. owl:inverseOf. 定义某个属性的相反关系。例如,定义“父母”的相反关系是“子女”,若A是B的父母,那么B肯定是A的子女。
本体映射词汇:
1. owl:equivalentClass. 表示某个类和另一个类是相同的。
2. owl:equivalentProperty. 表示某个属性和另一个属性是相同的。
3. owl:sameAs. 表示两个实体是同一个实体。
假设在一个庞大的数据库中存储了大量人物关系,很多关系是单向的,比如A的父亲是B,但是B的子女却为空,如下:

这时候如果我们用inversOf来表示hasParent和hasChild互为逆关系,那么上图可以表示为:
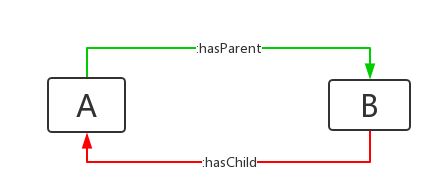
绿色的关系是RDF中真实存在的,红色的关系是推理得到的。
罗纳尔多那张图可表示为:

数据属性用青色表示,对象属性用蓝色表示。
本体建模
需要下载 protégé 来构建本体,具体操作方式请参阅知乎专栏 来一步步操作。这里我们直接从github下载相关文件,并将其重命名为ontology.owl,这将会在jena推理,检索中用到。
关系数据库到RDF
相当多送入知识图谱的数据是非结构化数据(直接从网络上爬取得),这里为了简化操作,只操作从关系型数据库中的结构化数据。我们使用 DQRQ 来把mysql中的数据转化为RDF。
下载D2RQ,进入其目录,运行下面的命令生成默认的mapping文件:
generate-mapping -u root -o kg_demo_movie_mapping.ttl jdbc:mysql:///kg_demo_movie
root是mysql的用户名,-欧威输出文件的路径与名称。jdbc:mysql:///kg_demo_movie是需要映射的数据库。生成mapping文件后,我们再根据自己的本体来修改mapping文件。参考相关文档(The D2RQ Mapping Language)。
然后使用命令来了将数据转化为RDF:
.\dump-rdf.bat -o kg_demo_movie.nt .\kg_demo_movie_mapping.ttl
kg_demo_movie.nt是RDF文件。
D2R2与SPARQL endpoint交互
D2RQ把SPARQL查询,按照mapping文件,翻译成SQL语句完成查询,然后把结果返回给用户。如下是D2RQ Server的架构图:

进入d2rq目录,启动D2RQ Server:
d2r-server kg_demo_movie_mapping.ttl
打开http:localhost:2020,可以看到如下界面:
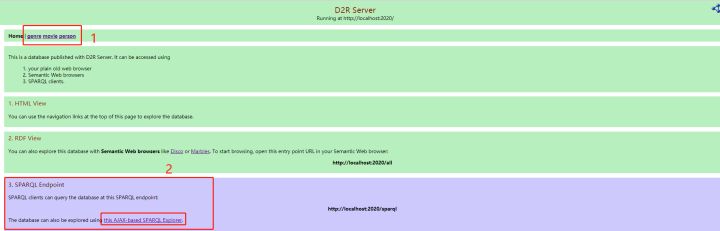
好了,可以在浏览器中查询了。
Apache Jena SPARQL endpoint推理
D2RQ开启endpoint服务,有两个问题:不支持直接将RDF通过endpoint发布在网上,不支持推理。下面的Apache Jena 就派上用场了,它用于构建语义网与链接数据应用。
jena的版本不同,操作也有很大的差异,这里推荐知识图谱-给AI装个大脑 和博客1与博客2 来操作。
DEMO 演示
代码从github 来下载,项目的目录结构为:
kg_demo_movie/
crawler/
movie_crawler.py
__init__.py
tradition2simple/
langconv.py
traditional2simple.py
zh_wiki.py
__init__.py
KB_query/
jena_sparql_endpoint.py
query_main.py
question2sparql.py
question_temp.py
word_tagging.py
external_dict/
csv2txt.py
movie_title.csv
movie_title.txt
person_name.csv
person_name.txt
__init__.py
进入KB_query目录,运行query_main.py,将会看到如下的交互界面:

全文参阅知乎专栏 知识图谱-给AI装个大脑 与 从零构建知识图谱