原文链接 http://codepub.cn/2015/08/04/Based-on-the-extended-version-of-synonyms-Cilin-word-similarity-computing/
注:以下为加速网络访问所做的原文缓存,经过重新格式化,可能存在格式方面的问题,或偶有遗漏信息,请以原文为准。
词语相似度计算
词义相似度计算在很多领域中都有广泛的应用,例如信息检索、信息抽取、文本分类、词义排歧、基于实例的机器翻译等等。国内目前主要是使用知网和同义词词林来进行词语的相似度计算。
本文主要是根据《基于同义词词林的词语相似度计算方法--田久乐》论文中所提出的分层算法实现相似度计算,程序采用Java语言编写。
同义词词林扩展版
《同义词词林》是梅家驹等人于1983年编纂而成,这本词典中不仅包括了一个词语的同义词,也包含了一定数量的同类词,即广义的相关词。《同义词词林扩展版》是由哈尔滨工业大学信息检索实验室所重新修订所得。该版收录词语近7万条,全部按意义进行编排,是一部同义类词典。
同义词词林按照树状的层次结构把所有收录的词条组织到一起,把词汇分成大、中、小三类,大类有12个,中类有97个,小类有1400个。每个小类里都有很多的词,这些词又根据词义的远近和相关性分成了若干个词群(段落)。每个段落中的词语又进一步分成了若干个行,同一行的词语要么词义相同,要么词义有很强的相关性。
《同义词词林》提供了5层编码,第1级用大写英文字母表示;第2级用小写英文字母表示;第3级用二位十进制整数表示;第4级用大写英文字母表示;第5级用二位十进制整数表示。例如: Cb30A01= 这里 这边 此地 此间 此处 此 Cb30A02# 该地 该镇 该乡 该站 该区 该市 该村 Cb30A03@ 这方
分层及编码表如下所示
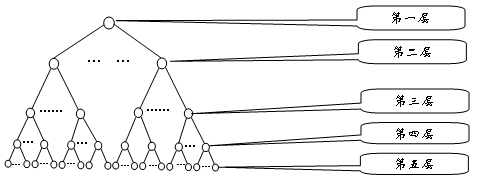
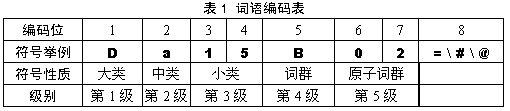
由于第5级有的行是同义词,有的行是相关词,有的行只有一个词,分类结果需要特别说明,可以分出具体的3种情况。使用特殊符号对这3种情况进行区别对待,所以第8位的标记有3种,分别是“=”代表“相等”、“同义”;“#”代表“不等”、“同类”,属于相关词语;“@”代表“自我封闭”、“独立”,它在词典中既没有同义词,也没有相关词。
在对文本内容进行相似度计算中,采用该论文中给出的计算公式,两个义项的相似度用Sim表示
若两个义项不在同一棵树上,Sim(A,B)=f
若两个义项在同一棵树上:
若在第2层分支,系数为a Sim(A,B)=1*a*cos*(n*π/180)((n-k+1)/n)
若在第3层分支,系数为b Sim(A,B)=1*1*b*cos*(n*π/180)((n-k+1)/n)
若在第4层分支,系数为c Sim(A,B)=1*1*1*c×cos*(n*π/180)((n-k+1)/n)
若在第5层分支,系数为d Sim(A,B)=1*1*1*1*d*cos*(n*π/180)((n-k+1)/n)
当编码相同,而只有末尾是“#”时,那么认为其相似度为e。
例如Ad02B04# 非洲人 亚洲人 则其相似度为e。
其中n是分支层的节点分支总数,k是两个分支间的距离。
如:人 Aa01A01= 和 少儿 Ab04B01=
以A开头的子分支只有14个,分别是Aa...,Ab...,Ac... ——— An...,而不是以A开头的所有结点的个数,所以n=14;在第2层分支上,人的编码是a,少儿的编码是b,a和b之间差1,所以k=1。
该文献中给出的参数值为a=0.65,b=0.8,c=0.9,d=0.96,e=0.5,f=0.1。
Java代码实现
package cn.codepub.algorithms.similarity.cilin;
import com.google.common.base.Preconditions;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang3.StringUtils;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream;
import java.util.*;
import static java.lang.Math.PI;
import static java.lang.Math.cos;
/**
* <p>
* Created with IntelliJ IDEA. 2015/8/2 21:54
* </p>
* <p>
* ClassName:WordSimilarity 同义词词林扩展版计算词语相似度
* </p>
* <p>
* Description:<br/>
* "=" 代表 相等 同义 <br/>
* "#" 代表 不等 同类 属于相关词语 <br/>
* "@" 代表 自我封闭 独立 它在词典中既没有同义词, 也没有相关词 <br/>
* </P>
*
* @author Wang Xu
* @version V1.0.0
* @since V1.0.0
*/
@Log4j2
//注意使用Log4j2的注解,那么在pom中必须引入2.x版本的log4j,如果使用Log4j注解,pom中引入1.x版本的log4j
//相应的配置文件也要一致,2.x版本配置文件为log4j2.xml,1.x版本配置文件为log4j.xml
public class WordSimilarity {
/**
* when we use Lombok's Annotation, such as @Log4j
*
* @Log4j <br/>
* public class LogExample {
* }
* <p>
* will generate:
* public class LogExample {
* private static final org.apache.logging.log4j.Logger log = org.apache.logging.log4j.Logger.getLogger(LogExample.class);
* }
* </p>
*/
//定义一些常数先
private static final double a = 0.65;
private static final double b = 0.8;
private static final double c = 0.9;
private static final double d = 0.96;
private static final double e = 0.5;
private static final double f = 0.1;
private static final double degrees = 180;
//存放的是以词为key,以该词的编码为values的List集合,其中一个词可能会有多个编码
private static Map<String, ArrayList<String>> wordsEncode = new HashMap<String, ArrayList<String>>();
//存放的是以编码为key,以该编码多对应的词为values的List集合,其中一个编码可能会有多个词
private static Map<String, ArrayList<String>> encodeWords = new HashMap<String, ArrayList<String>>();
/**
* 读取同义词词林并将其注入wordsEncode和encodeWords
*/
private static void readCiLin() {
InputStream input = WordSimilarity.class.getClass().getResourceAsStream("/cilin.txt");
List<String> contents = null;
try {
contents = IOUtils.readLines(input);
for (String content : contents) {
content = Preconditions.checkNotNull(content);
String[] strsArr = content.split(" ");
String[] strs = Preconditions.checkNotNull(strsArr);
String encode = null;
int length = strs.length;
if (length > 1) {
encode = strs[0];//获取编码
}
ArrayList<String> encodeWords_values = new ArrayList<String>();
for (int i = 1; i < length; i++) {
encodeWords_values.add(strs[i]);
}
encodeWords.put(encode, encodeWords_values);//以编码为key,其后所有值为value
for (int i = 1; i < length; i++) {
String key = strs[i];
if (wordsEncode.containsKey(strs[i])) {
ArrayList<String> values = wordsEncode.get(key);
values.add(encode);
//重新放置回去
wordsEncode.put(key, values);//以某个value为key,其可能的所有编码为value
} else {
ArrayList<String> temp = new ArrayList<String>();
temp.add(encode);
wordsEncode.put(key, temp);
}
}
}
} catch (IOException e) {
e.printStackTrace();
System.err.println("load dictionary failed!");
log.error(e.getMessage());
}
}
/**
* 对外暴露的接口,返回两个词的相似度的计算结果
*
* @param word1
* @param word2
* @return 相似度值
*/
public static double getSimilarity(String word1, String word2) {
//在计算时候再加载,实现懒加载
readCiLin();
//如果比较词没有出现在同义词词林中,则相似度为0
if (!wordsEncode.containsKey(word1) || !wordsEncode.containsKey(word2)) {
return 0;
}
//获取第一个词的编码
ArrayList<String> encode1 = getEncode(word1);
//获取第二个词的编码
ArrayList<String> encode2 = getEncode(word2);
double maxValue = 0;//最终的计算结果值,取所有相似度里面结果最大的那个
for (String e1 : encode1) {
for (String e2 : encode2) {
log.info(e1);
log.info(e2);
String commonStr = getCommonStr(e1, e2);
int length = StringUtils.length(commonStr);
double k = getK(e1, e2);
double n = getN(commonStr);
log.info("k-->" + k);
log.info("n-->" + n);
log.info("encode length-->" + length);
double res = 0;
//如果有一个以“@”那么表示自我封闭,肯定不在一棵树上,直接返回f
if (e1.endsWith("@") || e2.endsWith("@") || 0 == length) {
if (f > maxValue) {
maxValue = f;
}
continue;
}
if (1 == length) {
//说明在第二层上计算
res = a * cos(n * PI / degrees) * ((n - k + 1) / n);
} else if (2 == length) {
//说明在第三层上计算
res = b * cos(n * PI / degrees) * ((n - k + 1) / n);
} else if (4 == length) {
//说明在第四层上计算
res = c * cos(n * PI / degrees) * ((n - k + 1) / n);
} else if (5 == length) {
//说明在第五层上计算
res = d * cos(n * PI / degrees) * ((n - k + 1) / n);
} else {
//注意不存在前面七个字符相同,而结尾不同的情况,所以这个分支一定是8个字符都相同,那么只需比较结尾即可
if (e1.endsWith("=") && e2.endsWith("=")) {
//说明两个完全相同
res = 1;
} else if (e1.endsWith("#") && e2.endsWith("#")) {
//只有结尾不同,说明结尾是“#”
res = e;
}
}
log.info("res: " + res);
if (res > maxValue) {
maxValue = res;
}
}
}
return maxValue;
}
/**
* 判断一个词在同义词词林中是否是自我封闭的,是否是独立的
*
* @param source
* @return
*/
private boolean isIndependent(String source) {
Iterator<String> iter = wordsEncode.keySet().iterator();
while (iter.hasNext()) {
String key = iter.next();
if (StringUtils.equalsIgnoreCase(key, source)) {
ArrayList<String> values = wordsEncode.get(key);
for (String value : values) {
if (value.endsWith("@")) {
return true;
}
}
}
}
return false;
}
/**
* 根据word的内容,返回其对应的编码
*
* @param word
* @return
*/
protected static ArrayList<String> getEncode(String word) {
return wordsEncode.get(word);
}
/**
* 计算N的值,N表示所在分支层分支数,如:人 Aa01A01= 和 少儿 Ab04B01=,以A开头的子分支只有14个
* 这一点在论文中说的非常不清晰,所以以国人的文章进行编码真是痛苦
*
* @param encodeHead 输入两个字符串的公共开头
* @return 经过计算之后得到N的值
*/
protected static int getN(String encodeHead) {
int length = StringUtils.length(encodeHead);
switch (length) {
case 1:
return getCount(encodeHead, 2);
case 2:
return getCount(encodeHead, 4);
case 4:
return getCount(encodeHead, 5);
case 5:
return getCount(encodeHead, 7);
default:
return 0;
}
}
protected static int getCount(String encodeHead, int end) {
Set<String> res = new HashSet<String>();
Iterator<String> iter = encodeWords.keySet().iterator();
while (iter.hasNext()) {
String curr = iter.next();
if (curr.startsWith(encodeHead)) {
String temp = curr.substring(0, end);
if (res.contains(temp)) {
continue;
} else {
res.add(temp);
}
}
}
return res.size();
}
/**
* @param encode1 第一个编码
* @param encode2 第二个编码
* @return 这两个编码对应的分支间的距离,用k表示
*/
protected static int getK(String encode1, String encode2) {
String temp1 = encode1.substring(0, 1);
String temp2 = encode2.substring(0, 1);
if (StringUtils.equalsIgnoreCase(temp1, temp2)) {
temp1 = encode1.substring(1, 2);
temp2 = encode2.substring(1, 2);
} else {
return Math.abs(temp1.charAt(0) - temp2.charAt(0));
}
if (StringUtils.equalsIgnoreCase(temp1, temp2)) {
temp1 = encode1.substring(2, 4);
temp2 = encode2.substring(2, 4);
} else {
return Math.abs(temp1.charAt(0) - temp2.charAt(0));
}
if (StringUtils.equalsIgnoreCase(temp1, temp2)) {
temp1 = encode1.substring(4, 5);
temp2 = encode2.substring(4, 5);
} else {
return Math.abs(Integer.valueOf(temp1) - Integer.valueOf(temp2));
}
if (StringUtils.equalsIgnoreCase(temp1, temp2)) {
temp1 = encode1.substring(5, 7);
temp2 = encode2.substring(5, 7);
} else {
return Math.abs(temp1.charAt(0) - temp2.charAt(0));
}
return Math.abs(Integer.valueOf(temp1) - Integer.valueOf(temp2));
}
/**
* 获取编码的公共部分字符串
*
* @param encode1
* @param encode2
* @return
*/
protected static String getCommonStr(String encode1, String encode2) {
int length = StringUtils.length(encode1);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < length; i++) {
if (encode1.charAt(i) == encode2.charAt(i)) {
sb.append(encode1.charAt(i));
} else {
break;
}
}
int sbLen = StringUtils.length(sb);
//注意第三层和第五层均有两个字符,所以长度不可能出现3和6的情况
if (sbLen == 3 || sbLen == 6) {
sb.deleteCharAt(sbLen - 1);
}
return String.valueOf(sb);
}
@Test
public void testGetN() {
readCiLin();
int a = getN("A");
System.out.println(a);
}
@Test
public void testGetK() {
int k = getK("Aa01A01=", "Aa01A01=");
System.out.println(k);
}
@Test
public void testGetCommonStr() {
String commonStr = getCommonStr("Aa01A01=", "Aa01A03=");
System.out.println(commonStr);
}
@Test
public void testGetSimilarity() {
readCiLin();
double similarity = getSimilarity("人民", "国民");
System.out.println("人民--" + "国民:" + similarity);
similarity = getSimilarity("人民", "群众");
System.out.println("人民--" + "群众:" + similarity);
similarity = getSimilarity("人民", "党群");
System.out.println("人民--" + "党群:" + similarity);
similarity = getSimilarity("人民", "良民");
System.out.println("人民--" + "良民:" + similarity);
similarity = getSimilarity("人民", "同志");
System.out.println("人民--" + "同志:" + similarity);
similarity = getSimilarity("人民", "成年人");
System.out.println("人民--" + "成年人:" + similarity);
similarity = getSimilarity("人民", "市民");
System.out.println("人民--" + "市民:" + similarity);
similarity = getSimilarity("人民", "亲属");
System.out.println("人民--" + "亲属:" + similarity);
similarity = getSimilarity("人民", "志愿者");
System.out.println("人民--" + "志愿者:" + similarity);
similarity = getSimilarity("人民", "先锋");
System.out.println("人民--" + "先锋:" + similarity);
}
@Test
public void testGetSimilarity2() {
readCiLin();
double similarity = getSimilarity("非洲人", "亚洲人");
System.out.println(similarity);
double similarity1 = getSimilarity("骄傲", "仔细");
System.out.println(similarity1);
}
}
说明,词语相似度是个数值,一般取值范围在[0,1]之间,在原论文中,使用cos函数计算主要是将值归一化到[0,1]之间,可以将cos函数看作是一个调节因子。
testGetSimilarity的测试结果如下所示:
人民--国民:1.0
人民--群众:0.9576614882494312
人民--党群:0.8978076452338418
人民--良民:0.7182461161870735
人民--同志:0.6630145969121822
人民--成年人:0.6306922220793977
人民--市民:0.5405933332109123
人民--亲属:0.36039555547394153
人民--志愿者:0.22524722217121346
人民--先锋:0.18019777773697077
本文使用的是同义词词林的扩展版,而原论文使用的是同义词词林,由于两者存在微小差距,所以本文计算结果与论文中的计算结果存在稍许误差,如果算法没错,这是可以理解的!
以上仅为个人理解,如若发现错误,欢迎大家积极留言指正!
代码已经推送到GitHub上了,地址点我。注意在文章末尾所注的参考资料中的链接里面的计算方法在求n的时候存在错误,希望莫要受其误导!
参考文献 [1] http://www.cnblogs.com/einyboy/archive/2012/09/09/2677265.html