原文链接 https://lanffy.github.io/2017/07/23/Python-And-BeautifulSoup4
注:以下为加速网络访问所做的原文缓存,经过重新格式化,可能存在格式方面的问题,或偶有遗漏信息,请以原文为准。

Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
它可以通过页面标签和属性定位到指定的标签元素,并获取元素中的值。在实际的爬取应用中,非常方便。下面介绍一些常用的技巧。
安装
安装Beautiful Soup4
Debain或Ubuntu
新版的Debain或ubuntu,可以通过系统的软件包管理来安装:
apt-get install Python-bs4
Beautiful Soup 4 通过PyPi发布,所以如果你无法使用系统包管理安装,那么也可以通过 easy_install 或 pip 来安装.包的名字是 beautifulsoup4 ,这个包兼容Python2和Python3.
easy_install beautifulsoup4pip install beautifulsoup4
如果你没有安装 easy_install 或 pip ,那你也可以 下载BS4的源码 ,然后通过setup.py来安装.
Python setup.py install
Mac
- 安装pip:
sudo easy_install pip - 用pip安装BeautifulSoup4:
pip install BeautifulSoup4
Windows
略
安装解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是lxml .根据操作系统不同,可以选择下列方法来安装lxml:
apt-get install Python-lxmleasy_install lxmlpip install lxml
另一个可供选择的解析器是纯Python实现的html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
apt-get install Python-html5libeasy_install html5libpip install html5lib
下表列出了主要的解析器,以及它们的优缺点:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml", "xml"]) |
速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") |
最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
提示: 如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的,查看解析器之间的区别了解更多细节
应用
下面简单介绍一些bs4的常用技巧
抓取标签列表
例如,要抓取链家小区列表页的区域筛选项,如下图:
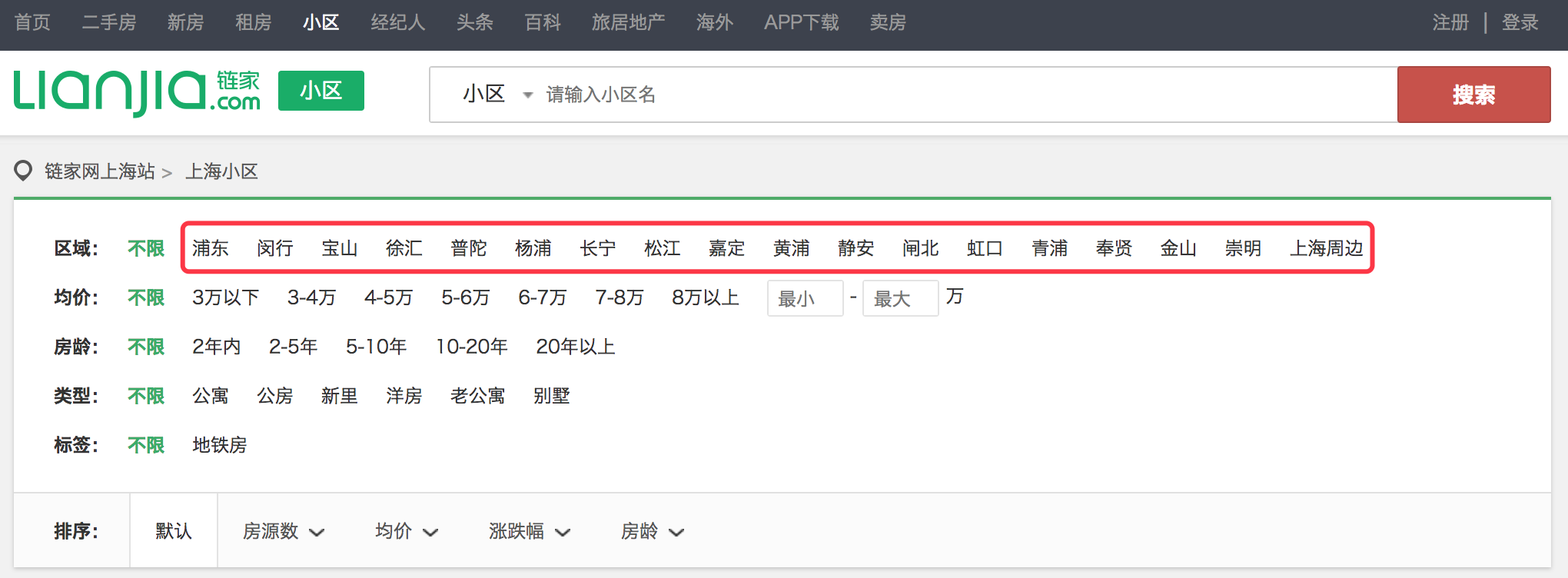
代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
url = "http://sh.lianjia.com/xiaoqu/"
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
headers = {'User-Agent': user_agent}
session = requests.session()
page = session.get(url, headers=headers)
soup = BeautifulSoup(page.text,'html.parser')#以html的方式解析页面,返回一个soup对象
dllist = soup.find_all('div', attrs={'class': 'option-list gio_district'}) #返回所有的class=option-list gio_district 的div对象
for dl in dllist:
alist = dl.find_all('a', attrs={'class': ''}) #在上面的div标签中,查找class为空的a标签
for a in alist:
print(a.string)
抓取单个标签
例如,要抓取链家小区列表页的小区个数,如下图:
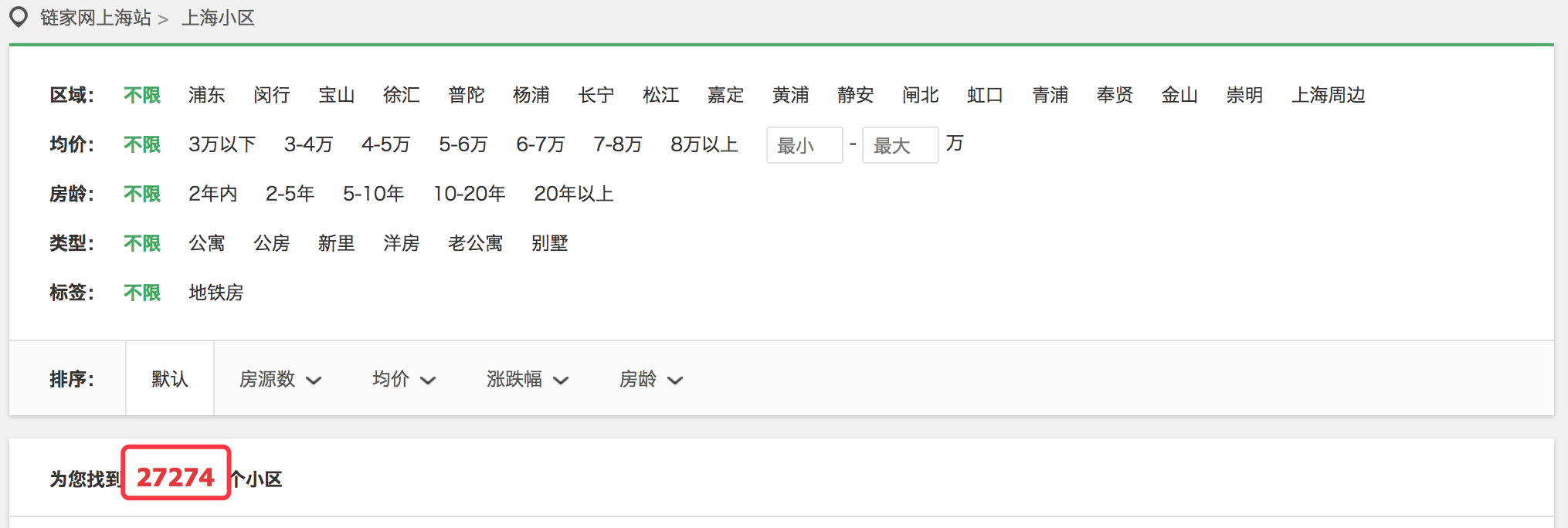
代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
url = "http://sh.lianjia.com/xiaoqu/"
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
headers = {'User-Agent': user_agent}
session = requests.session()
page = session.get(url, headers=headers)
soup = BeautifulSoup(page.text,'html.parser')#以html的方式解析页面,返回一个soup对象
page_community_count_div = soup.find('div', attrs={'class':'list-head clear'})
p_community_count = page_community_count_div.find('span').string
print(p_community_count)
根据正则匹配抓取标签
例如,要抓取链家小区列表页的小区名称,如下图:
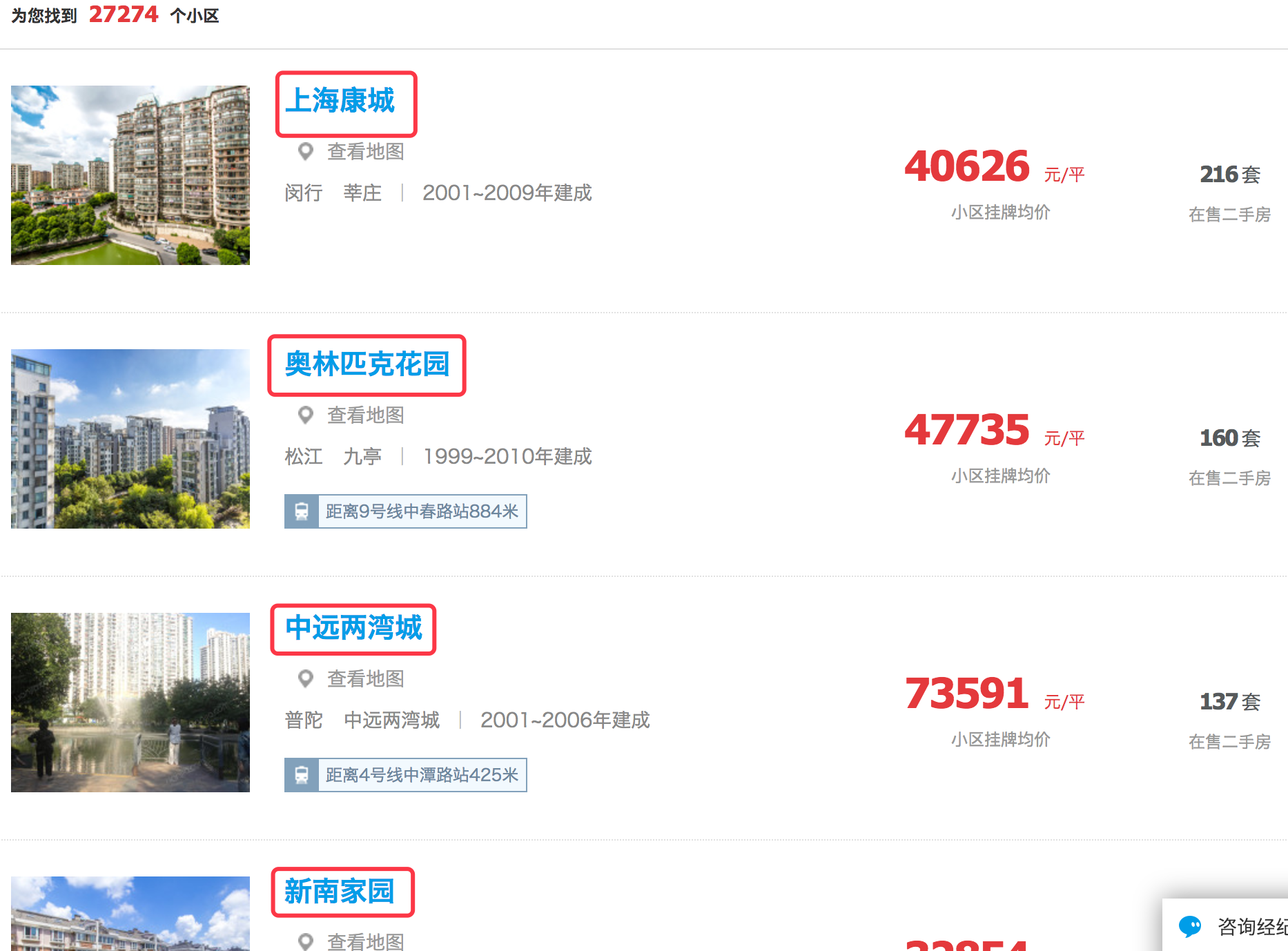
代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
url = "http://sh.lianjia.com/xiaoqu/"
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
headers = {'User-Agent': user_agent}
session = requests.session()
page = session.get(url, headers=headers)
soup = BeautifulSoup(page.text,'html.parser')#以html的方式解析页面,返回一个soup对象
community_div = soup.find_all('a', attrs={'name':'selectDetail', 'title':re.compile(".*")})
for a in community_div:
print(a.string)
这里仅仅只是介绍了比较常用的一部分功能,更多应用请查看BeautifulSoup4的官方文档。