原文链接 http://codepub.cn/2015/09/26/An-Automatic-Annotation-Method-for-Emergency-Text-Corpus/
注:以下为加速网络访问所做的原文缓存,经过重新格式化,可能存在格式方面的问题,或偶有遗漏信息,请以原文为准。
自序
人生天地间,若白驹之过隙,忽然而已。无奈诸多俗务缠身,难得清闲。一直都是忙忙碌碌,然而碌碌无为,只顾埋头前行,偶有机会驻足回首,实乃吾之大幸。
因为我的父母是地地道道、兀兀穷年的农民,我这一路摸爬滚打全靠自己不断摸索总结。在人生的道路上,我一直很感谢能给我人生上面指导的人,而技术上面的指导却不是我迫切需要的,技术可以通过Google获得,然而人生的经验却只有过来人才能予以传授。不过我还是信奉我那句话,有变化就有机遇,一定要勇于拥抱变化。
我一直自认为是一个简简单单、没有心机、毫无城府、专心搬砖的人,所以坐下来细细思索,发现没有其它东西以飨读者,唯有一点点技术心得值得予以分享。下面就介绍一下在研究生期间所做的一点点工作。
CEC简介
CEC语料库
Chinese Emergency Corpus简称CEC,中文名称为中文突发事件语料库,是根据上海大学刘宗田教授所提出的《面向事件的本体研究》由人工标注所构建完成,目前整个语料库在重新进行了编码转换、XML格式化、错误修复之后托管在GitHub上了,地址点我。
事件的定义是什么
事件指在某个特定的时间和环境下发生的、由若干角色参与、表现出若干动作特征的一件事情。形式上,事件可表示为e,定义为一个六元组:e ::= (A, O, T, P, S, L)其中,事件六元组中的元素称为事件要素,分别表示动作(Action)、对象(Object)、时间(Time)、地点(Place)、状态(Status)、语言表现(Language Expressions)。
- A(动作):A表示事件所包含的动作或动作序列的集合,在文本中,动作通常是作为识别一个事件的触发词
- O(对象):O表示一个事件中的对象集合,包括事件中所有的参与者和涉及到的对象。对象可分别是动作的施动者(主体)和受动者(客体)
- T(时间):T表示事件发生的时刻或时间段,时间分为绝对时间和相对时间,两类时间都可以通过计算转换成形如[t1,t2]的序偶表示,以此描述事件的开始、发展和结束时间,当开始时间和结束时间一样时,表示事件发生在瞬间
- P(地点):表示事件发生的地点;例如:在小池塘里游泳, 场所:小池塘, 场所特征:水中
- S(状态):表示事件发生过程中对象的状态集合,由事件发生的前置条件、后置结果集合组成。前置条件指为进行该事件, 各要素应当或可能满足的约束条件, 它们可以是事件发生的触发条件;中间断言指事件发生过程的中间状态各要素满足的条件;事件发生后,事件各要素将引起变化或者各要素状态的变迁, 这些变化和变迁后的结果, 将成为事件的后置条件。
- L(语言表现):事件的语言表现规律, 包括核心词集合、核心词表现、核心词搭配等。核心词是事件在句子中常用的标志性词汇。核心词表现则为在句子中各要素的表示与核心词之间的位置关系。核心词搭配是指核心词与其他词汇的固有的搭配。可以为事件附上不同语言种类的表现, 例如中文、英文、法文等等。
在事件的六个要素中,前五个要素是事件的内在要素。
CEC如何构建
事件本体是以“事件”为认知单元,研究事件的组成以及事件之间的关系,并对事件进行归纳和概括,形成事件类,进而构建事件本体模型。研究本体,必然要先构建语料库,所以在互联网上选取了突发事件语料来进行语料的事件标注,突发事件的分类体系,包括三个层次:一级4个大类(自然灾害类N、事故灾难类A、公共卫生事件P、社会安全事件S),二级33个子类,三级94个小类。我们标注的CEC语料库主要包括五类:地震、火灾、交通事故、恐怖袭击、食物中毒。合计332篇。
CEC标注标签规范
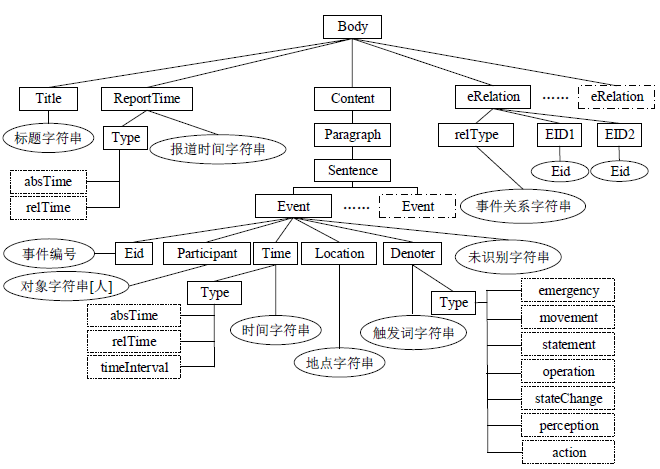
CEC标注样例
<Body>
<Title>成都网友称震感强烈 女同事当即哭泣</Title>
<ReportTime type="absTime">2008年05月12日16:15</ReportTime>
<Content>
<Paragraph>
<Sentence>
<Event eid="e1">
<Time type="relTime" tid="t1">5月12日14时28分</Time>,
<Location lid="l1">四川</Location>发生7.8级
<Denoter type="emergency" did="d1">地震</Denoter>。
</Event>
</Sentence>
<Sentence>
<Event eid="e2">
<Time type="relTime" tid="t2">15时50分</Time>,新民网
<Participant sid="s1">记者</Participant>网上
<Denoter type="action" did="d2">连线</Denoter>成都网友
<Participant oid="o2">姚先生</Participant>。
</Event>
</Sentence>
</Paragraph>
</Content>
<eRelation relType="Causal" cause_eid="e1" effect_eid="e5" />
</Body>
LTP(Language Technology Platform)平台云简介
语言技术平台(Language Technology Platform,LTP)是哈工大社会计算与信息检索研究中心历时十年研制的一整套开放中文自然语言处理系统。LTP制定了基于XML的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富、高效、高精度的中文自然语言处理模块(包括词法、句法、语义等5项中文处理核心技术,在多次国内外技术评测中获得优异成绩,特别是获得CoNLL 2009国际句法和语义分析联合评测的第一名),应用程序接口,可视化工具,以及能够以网络服务使用的语言技术云。学术版LTP已共享给500多家研究机构免费使用,百度、腾讯、华为、金山等企业付费使用LTP商业版本。2010年,LTP荣获行业最高奖--“钱伟长中文信息处理科学技术一等奖”。
语言技术平台的总体结构如下所示
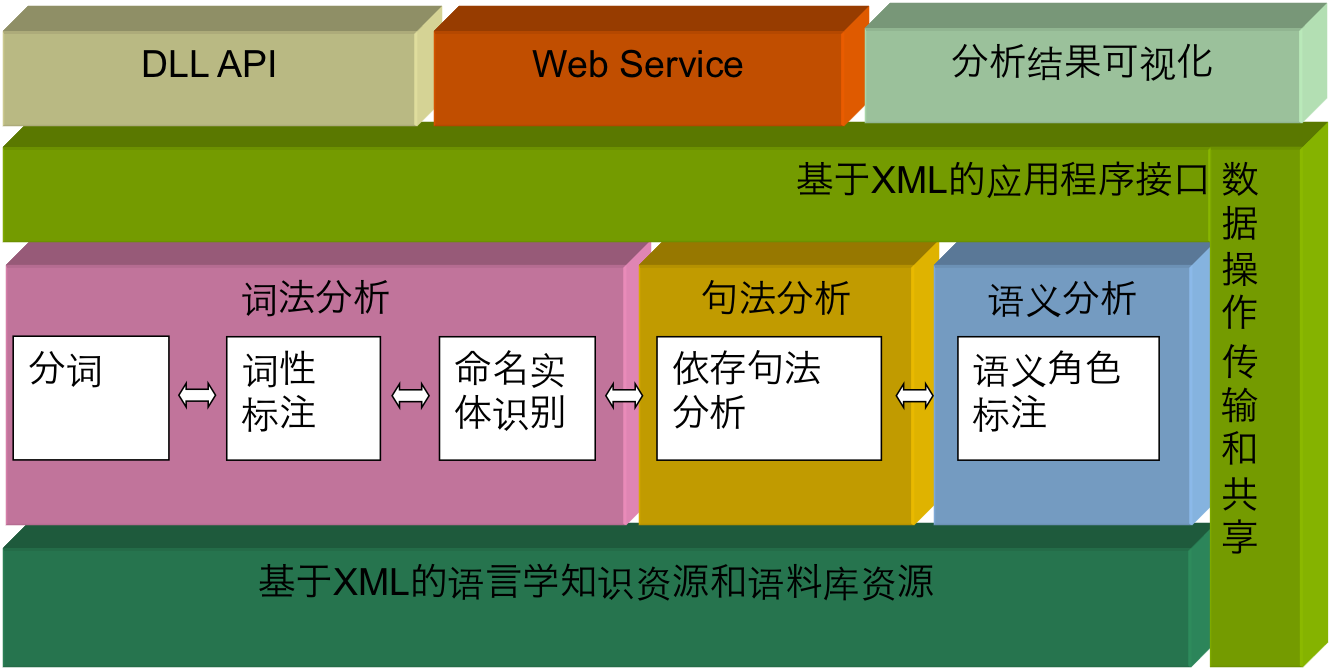
若想进一步了解,请点我进入LTP官网进行查看。
我的工作-用机器进行标注
在我们构建CEC的过程中全部由人工进行标注,先用网络爬虫从网络上爬取突发事件类的新闻报道,之后人工对事件的要素进行识别,然后添加对应的标签以及属性等。此过程费时费力,而且由于不同的人有不同的判断,易造成标注过程中的标准不一致,进而为整个语料库带来一些歧义性的标注内容,所以应该由机器进行初步的标注,人工在机器标注的基础之上进行深入细致的分析,修正等。
效果图
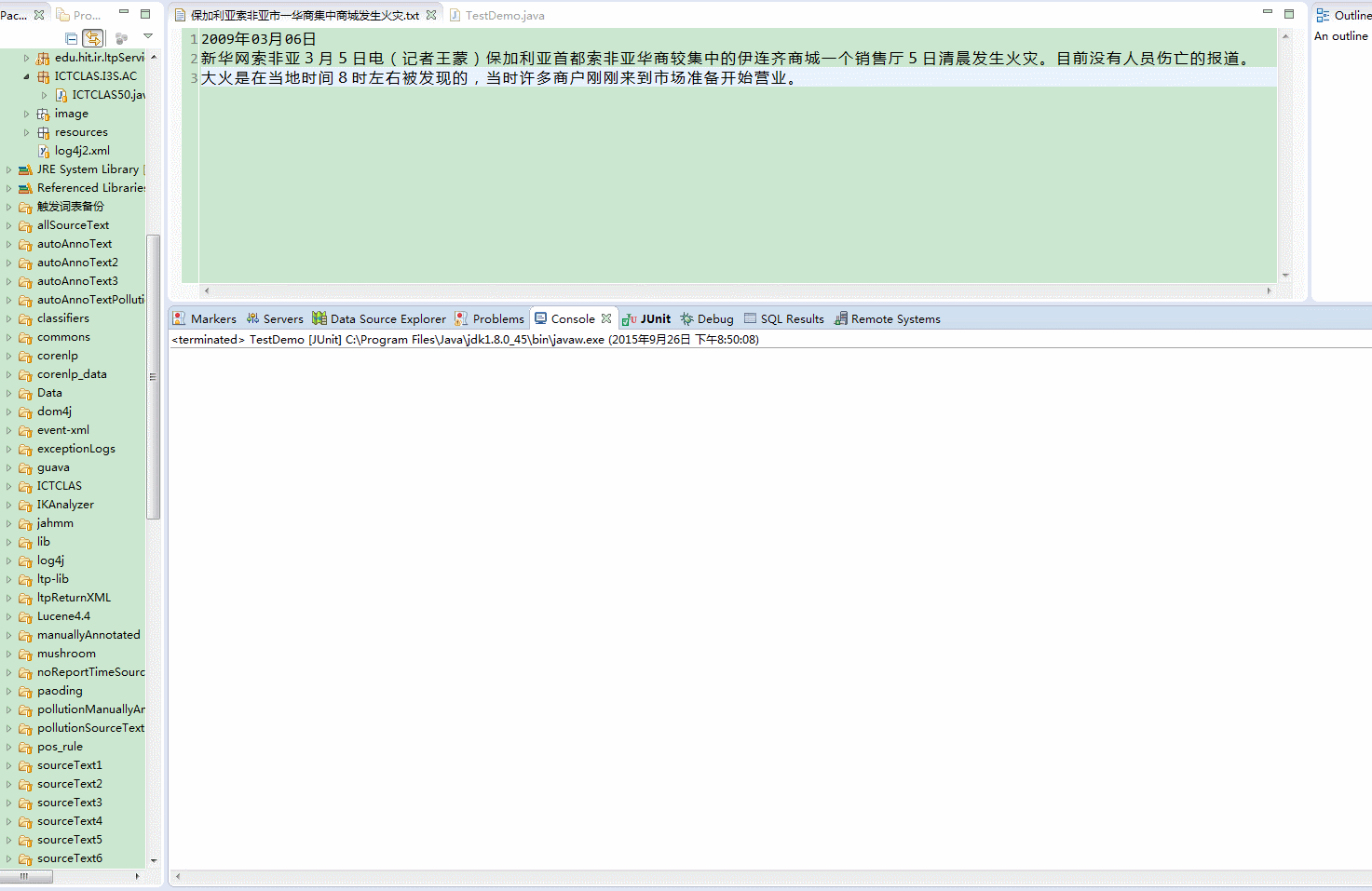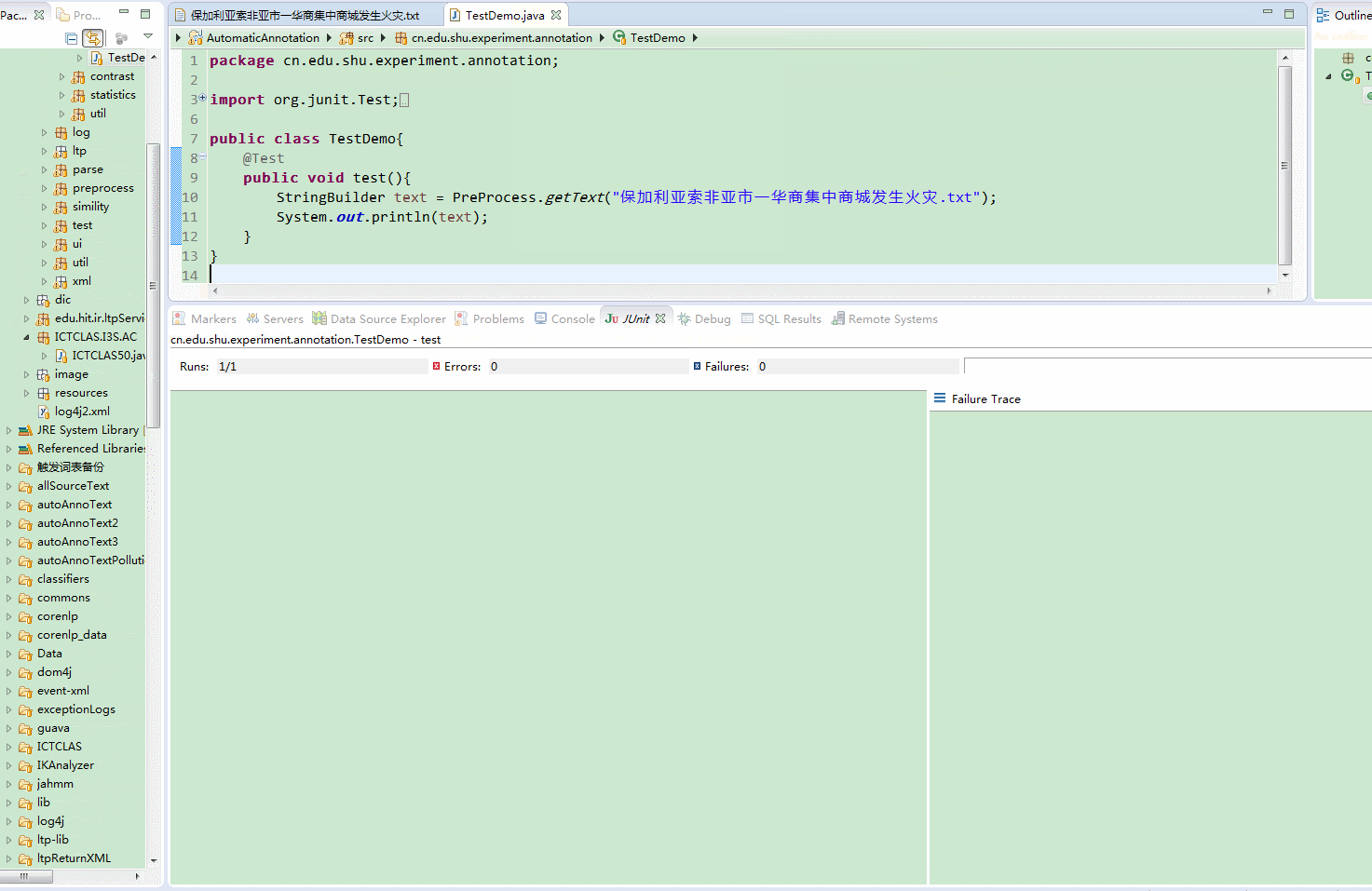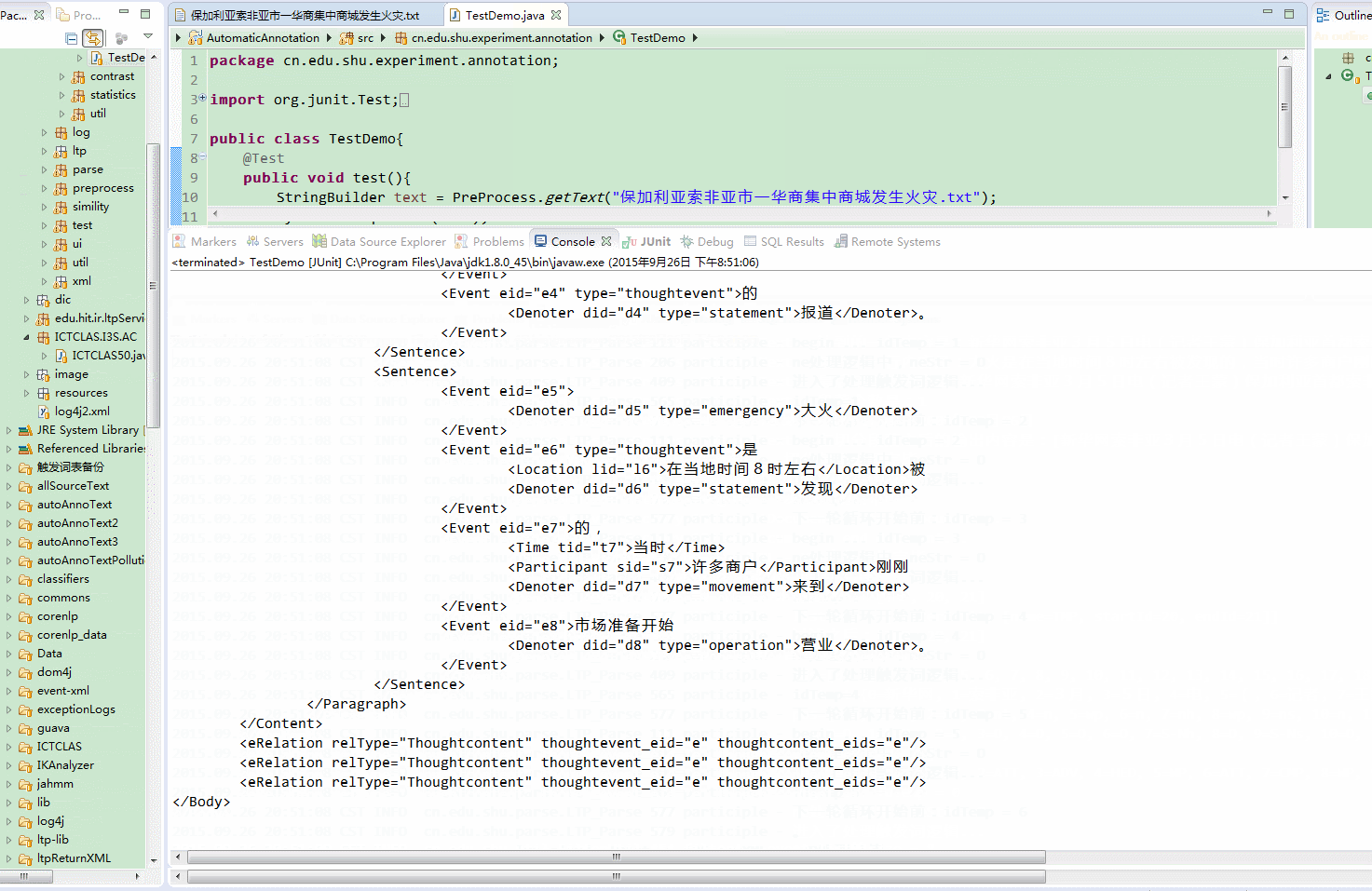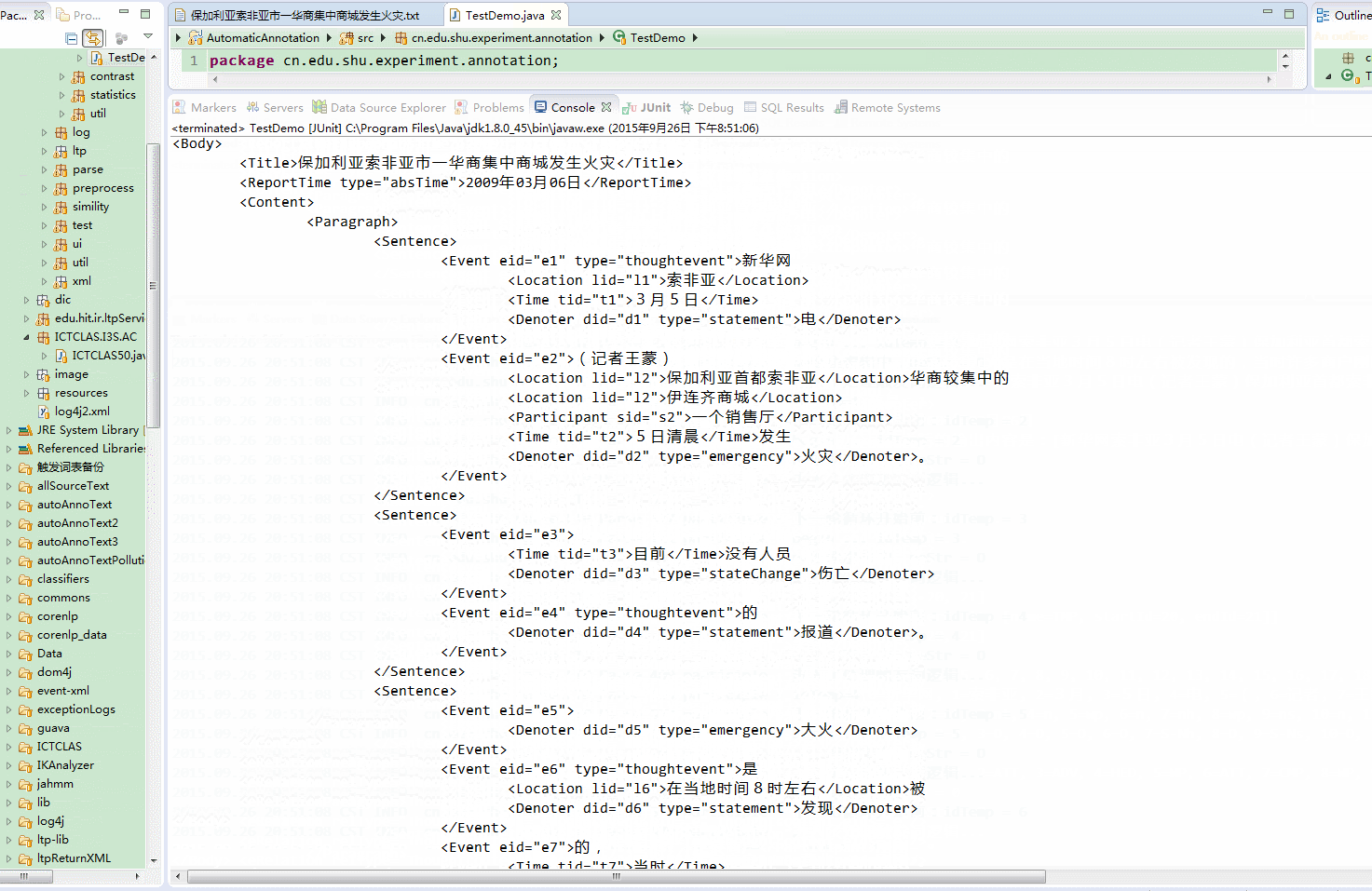
如何实现
挖掘事件要素规则
借助于人工构建的CEC语料库,使用LTP对CEC语料库中的原文本(未标注的文本)进行词性标注、命名实体识别、语义角色标注等一系列基础性工作,之后与CEC语料库进行对比,抽取出事件的每个要素所对应的词性、语义角色等,这样可以获取到大量的有序的词性集合以及语义角色集合,既然词性和语义角色标注都是有序的,那么很自然的想到利用序列模式挖掘算法对词性集合、语义角色集合进行频繁项集挖掘,我采用的是韩家炜于2004年提出的PrefixSpan序列模式挖掘算法,有兴趣的可以去读读他的论文,地址点我。
构建触发词表
根据触发词类型的不同,分别抽取出每一种类型的触发词构建成触发词表。在CEC语料库中触发词共有七种,分别是:突发事件(emergency) 、移动事件(movement)、声明类事件(statement)、原子动作事件(action) 、操作事件(operation) 、状态改变事件(stateChange)、感知事件(perception)。
使用同义词词林(扩展版)扩充触发词表
首先要知道为什么需要扩充触发词表?既然触发词表由CEC中抽取所得,限于CEC规模有限,触发词表的数量亦必然有限,那么需要使用同义词词林对其进行扩充,在扩充的过程中,并不是将与某个触发词是同义词的所有义项全部扩充进触发词表,而是有一定的阈值,对于满足一定阈值的同义词项才认为均是合法的,予以扩充。
用户自定义事件要素词典
同样的,我们不禁要问一下,为什么需要用户自定义要素词典呢?同样是限于CEC规模,挖掘的要素识别规则必然有限,亦不能涵盖大量未知的情况,所以需要人工定义事件要素词典,并且该词典可以采用倒序排列,按照文本串的长度由长到短排序,这样机器识别要素的时候,可以防止过分切分事件要素,类似于切词里面的正向最大切分。
本算法有一定的领域局限性,目前仅限于突发事件类的新闻报道,且准确率有待进一步提高,此为后话。有关实现的具体细节,请参考我的论文:《一种面向突发事件的文本语料自动标注方法》